二刷Java基础
java概述
概念
JDK(开发工具包):是提供开发人员是hi用的,java开发工具、包括JRE
JRE(运行环境):包括java虚拟机和所需要的核心类库,可以运行java程序
JVM:虚拟机
关键字:被java赋予了特殊的含义,所有字母都是小写
保留字:java尚未使用,但之后可能会作为关键字使用,命名时避开
标识符:给变量、方法、类等元素命名的字符
Java特点
- 纯粹的面向对象
- 类,对象
- 封装、集成、多态
- 健壮性
- 去掉了c中的指针
- 增加了垃圾回收机制
- 跨平台性
- JVM虚拟机
- Java代码–字节码文件–JVM虚拟机–操作系统–硬件
标识符
命名规则
- 26英文字符、0-9,_或$
- 数字不能开头
- 不能使用关键字和保留字
- 严格区分大小写,长度无限制
- 不能有空格
命名规范
包名:多单词组成全小写
类、接口名:多单词首字母大写
变量、方法名:第一个首字母小写,其他驼峰命名
常量名:全大写,多单词用下划线连接
变量
数据类型

整数类型(byte,short,int,long)

浮点型(float,double)
E表示10的多少次方,如E38就是10的38次方

字符类型(char)
2字节,用单引号括起来
- 声明一个字符
- 转义字符
'\n' - Unicode值表示值
String引用数据类型
可以与8中基本数据类型做运算,运算只能是+
3+4+"hello" ----> 7hello
"hello"+3+4 ----> hello34
String a = 4;//错
String a = 4+"";//对
类型转换
自动类型转换
(char、byte、short)–int–long–float–double
short s = 5;
s = s-2;//编译不通过,因为2是int,所以结果是Int
s = (short)(s-2);//通过,强制类型转换
强制类型转换
强转符()
如:double d1 = 12.9; int i2=12
进制转换
二进制转十进制
10101,从右往左:2^0^x1+2^1^x0+2^2^x1+2^3^x0+2^4^x1=21
十进制转二进制
21,除2取余的逆:商10余1,商5余0,商2余1,商1余0,商0余1
取逆:10101
二进制转八进制、十六进制
八进制:3个一位
十六进制:4个一位
原码、反码、补码:

基本语法
算术运算符
取余运算%
结果的符号与被模数符号相同
++,–
比较运算符
instanceof
检查是否是类的对象
如:Hello instanceof String 结果:true
逻辑运算符
&&,|| 短路与/或
^异或
判断两个是否不同,不同为true,同为false
位运算符
<<:左移,如:int i = 21; i<<2,结果:i=84,过程:21*2^2^
三元运算符
格式:(条件表达式)?表达式1:表达式2
如果条件为true,结果为表达式1,否则为2
流程控制
1.switch case
表达式中只能有6种数据类型:
byte、short、char、int、枚举、String
switch(表达式){
case 常量1:
语句;
break;//不加的话,会按顺下往下执行
case 常量2:
语句;
break;
default://最终兜底,可写可不写
语句;
break;
}
2.for
for(初始化条件;循环条件(boolean类型);迭代条件){
循环体
}
for(int i =1;i<=10;i++){
System.out.println("hello");
}
3.while(先判断后执行)
while(循环条件){
循环体
迭代条件
}
int i=1;
while(i<=10){
System.out.println("hello");
i++;
}
while(true)无限循环:使用break来跳出
4.do-while(先执行后判断)
do{
循环体
迭代条件
}while(循环条件)
数组
概述
- 是引用数据类型,元素可以是任何数据类型
- 在内存种开辟一整块内存空间
- 数组长度一旦确定,不能修改
- 角标从0开始
一维数组
初始化
必须指定长度,内存才会分配空间
//静态初始化 int[] array1; array1 = new int[]{1,2,3}; int arr3[] = {1,2,3}; //动态初始化 String[] array2 = new String[5]; //默认初始化值: 整型:0,浮点型:0.0,char:0,boolean:false,引用数据类型:null调用
array1[0]="小明"; //获取长度 array1.length //遍历,条件表达式没有等号 for(int i=0;i<array1.length;i++){ System.out.println(array[i]); }内存解析


二维数组
初始化
int[][] arr1 = new int[][]{{1,2,3},{1,2}}; int[][] arr2 = new int[3][2]; int[][] arr3 = new int[3][]; int[][] arr4 ={{1,2},{1,2,3}};调用
arr1[0][1] //获取长度 String[][] arr4 = {{1,2,3},{1,2,3,4},{1,1,1}} arr4.length//3 arr4[0].length//3 //遍历 for(int i= 0;i<arr4.length;i++){ for(int j = 0;j<arr4[i].length;j++){ System.out.println(arr4[i][j]); } }默认初始化值
int[][] arr = new int[4][3]外层元素:arr[0],地址值
内层元素:arr[0] [0],0
int[][] arr = new int[4][]外层元素:地址值
内层元素:空指针,因为没有指定内存空间
内存解析
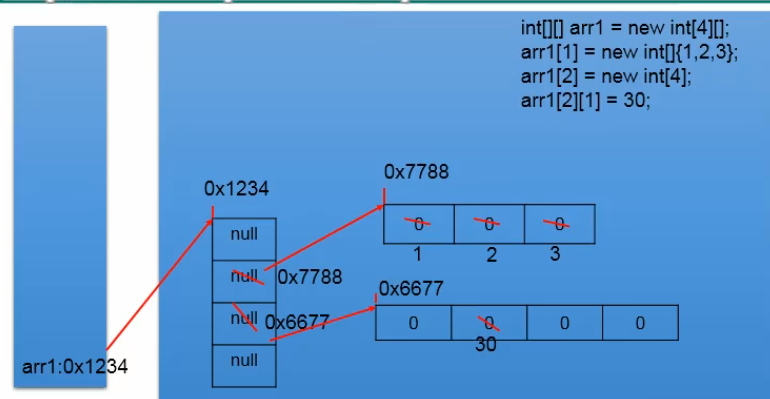
二维数组算法
/** *杨辉三角 *要求:1.打印一个10行杨辉三角 2.第一行有1个元素,第n行有n个元素 3.每一行的第一个元素和最后一个元素是1 4.从第三行开始,对于非第一个元素和最后一个元素, yanghui[i][j]=yanghui[i-1][j-1]+yanghui[i-1][j] **/ public void test(){ //声明并初始化数组 int[][] yangHui = new int[10][]; //给数组赋值 for(int i = 0;i<yangHui.length;i++){ yangHui[i] = new int[i+1]; //给首位元素赋值 yangHui[i][0]=yangHui[i][i]=1; //给中间赋值,这个判断语句可以省略,因为当i为0或1时,for判断语句也进不去 // if(i>1){ //从第二个数组开始,到倒数第二个数组结束 for(int j = 1;j<yangHui[i].length-1;j++){ yangHui[i][j]=yangHui[i-1][j-1]+yangHui[i-1][j] } //} } //遍历数组 for(int i = 0;i<yangHui.length;i++){ for(int j = 0;j<yangHui[i].length;j++){ System.out.println(yangHui[i][j]); } } }多维数组的使用 声明:int[] x,y[],以下允许通过编译的是 //首先,int[] x,是一个一维数组,y是一个二维数组 x[0] = y;//不可以,int=二维数组 y[0] = x;//可以,一维=一维 y[0][0] = x;//不可以,int = 一维 y[0][0] = x[0];//可以,int = int定义一个int型一维数组,包含10个元素,分别赋予随机整数,求所有元素的最大值最小值,和,平均值 要求:所有随机数都是两位数 公式:[a,b]的整数,(int)(Math.random()*(b-a+1)+a) //(int)(Math.random()*(99-10+1)+10) public void test(){ int[] arr = new int[10]; for(int i=0;i<arr.length;i++){ arr[i]=(int)(Math.random()*(99-10+1)+10) } //最大值 int max = arr[0]; for(int i=1;i<arr.length;i++){ if(max<arr[i]){ max=arr[i]; } } //最小值 int min = arr[0]; for(int i=1;i<arr.length;i++){ if(min>arr[i]){ min=arr[i]; } } //和 int sum = 0; for(int i=0;i<arr.length;i++){ sum+=arr[i]; } //平均值 int avg = sum/arr.length; }//数组复制 int[] arr1 = {1,2,3}; int[] arr2 = new int[arr1.length]; for(int i = 0;i<arr1.length;i++){ arr2[i]=arr1[i]; }//数组反转 int[] arr1 = {1,2,3}; for(int i = 0;i<arr1.length / 2;i++){ int temp = arr1[i]; arr1[i]=arr1[arr1.length-i-1]; arr1[arr1.length-i-1] = temp; }
数组查找
线性查找
public void test(){
String[] arr1 ={"a","b","c"}
String dest = "b";
boolean isFlag = true;
for(int i=0;i<arr1.length;i++){
if(dest.equals(arr1[i])){
System.out.println("找到了");
isFlag = false;
break;
}
}
if(isFlag){
System.out.println("没有找到")
}
}
二分法查找
//前提:要查找的数组必须是有序的
public void test(){
int[] arr1 = {-20,-10,-5,0,11,18,23,55};
int dest = -10;//要查找的数
boolean isFlag = true;
int head = 0;//起始索引
int end = arr1.length-1;//末索引
while(head<=end){
int middle = (head+end)/2;//中间索引
if(dest==arr1[middle]){
System.out.println("找到了,位置在"+middle);
ifFlag = false;
break;
}else if(dest>arr1[middle]){
head = middle+1;
}else{//dest<arr1[middle]
end = middle-1;
}
}
if(isFlag){
System.out.println("没有找到");
}
}
排序算法
算法的5大特征
- 有输入
- 有输出
- 有穷性:能结束,不是死循环
- 确定性:有确定含义,没有二义性
- 可行性:清楚可行
选择排序:堆排序
交换排序:==冒泡排序(n^2^)、快速排序(nlog2n)==,平均时间上:快速排序最佳
归并排序
//冒泡排序
public void test(){
int[] arr1 = {1,2,-20,-10,12,5,3,15};
for(int i = 0;i<arr1.length-1;i++){//负责控制几轮,8个元素,i<7,共7轮,第8轮就自己不需要排序
for(int j = 0;j<arr1.length-1-i;j++){//负责控制对比的次数,第一轮对比7次,第二轮对比6次
int temp = arr1[j];
arr1[j] = arr1[j+1];
arr1[j+1] = temp;
}
}
}
//快速排序
public static void quickSort(int[] arr,int left,int right){
int i =left;//先备份,保证ij变动,传入的参数不变
int j = right;
int key = arr[left];
int temp ;
if(i>j){
return;
}
if(arr.length=null||arr.length=0){
return;
}
while(i<j){
while(i<j&&arr[right]>=key){
j--;
}
while(i<j&&arr[left]<=key){
i++;
}
while(i<j){
t = arr[i];
arr[i] = arr[j];
arr[j] = t;
}
}
arr[left] = arr[i];
arr[i] = key;
quickSort(arr,left,j-1);
quickSort(arr,j+1,right);
}
Arrays工具类
| 1 | boolean equals(int[] a,int[] b) | 判断两个数组是否相等 |
|---|---|---|
| 2 | String toString(int[] a) | 输出数组信息 |
| 3 | void fill(int[] a,int val) | 将只等值填充到数组之中 |
| 4 | void sort(int[] a) | 对数组进行排序 |
| 5 | int binarySearch(int[] a,int key) | 对排序后的数组进行二分法检索指定的值 |
数组常见异常
- 数组角标越界异常:
ArrayIndexOutOfBoundsException - 空指针异常:
NullPointerException
面向对象
对象的内存分析
- 堆:存放对象实例(包括对象中的属性(成员变量))
- 栈:存放局部变量(保存在方法种的变量)
- 方法区:存放类信息、常量、静态变量
变量
成员变量与局部变量:
- 成员变量:类中的属性,加载到堆空间
- 局部变量:方法中的属性,加载到栈空间
- 成员变量有初始化值
- 局部变量没有初始化值,引用时需要显式赋值
方法
格式:权限修饰符 返回值类型 方法名(形参列表){方法体}
关键字[可选]:static、final、abstract
权限修饰符:private、缺省、protected、public(类内部,同一个包,不同包的子类,同一个工程)
重载
两同一不同:
同一个类,相同方法名,
参数列表不同:参数个数不同,参数类型不同
可变个数形参
允许直接定义能和多个实参类型相匹配的形参
public void show(String ... strs)
构造器
- 如果没有显式定义类的构造器的话,系统默认提供一个空参的构造器
- 一旦显示定义了类的构造器之后,系统就不会再提供空参的构造器
- 一个类至少会有一个构造器
关键字
this
在类中,this指的是这个类的对象,通过this.属性来调用对象的成员变量。一般情况下属性和形参重名才会使用。
也可以调用构造器,如this(),就是调用的空参,也可以写有参的this(id,age),一般都放在方法的首行
super
- 在子类的方法或构造器中,通过super.属性或super.方法,显式调用父类中声明的属性或方法
- 当子类和父类定义了同名的属性/方法,我们需要用
super.属性表示调用的是父类中声明的属性
static
- 静态的
- static可以用来修饰:属性(类变量)、方法、代码块、内部类
- 静态变量(类变量):
- 随着类加载而加载,早于对象的创建。
- 可以通过“类.静态变量”来调用
- 类不能调用实例变量
Student.name是不行的,如果是类变量可以
- 静态方法
- 随着类加载而加载,可以通过“类.静态方法”的方式进行调用
- 类不能调用非静态方法或属性
- 非静态方法可以调用静态方法和属性,也可以调用非静态
- 在静态方法内,不能使用this关键字,super关键字
- 什么时候声明static:属性被多个对象共享的,不会随对象而不同。操作静态属性的方法。工具类
final
可以用来修饰的结构:类、方法、变量
类:此类不能被继承
方法:此类不能被重写
变量:让其变为一个常量,不能再修改
修饰属性:显示初始化、代码块中初始化、构造器中初始化(用于值不一样的时候)
修饰局部变量:修饰形参时,表明形参是一个常量,当我们调用此方法,给常量形参赋予一个实参,以后调用以后就只能再方法体内使用该形参,不能进行重新赋值
代码块
- 作用:用于初始化类、对象
- 代码块只能用static修饰
- 静态代码块:
- 内部可以有输出语句
- 随着类的加载而执行,且只执行一次
- 类中可以定义多个静态代码块
- 静态代码块执行优先于非静态代码块
- 静态代码块内只能调用静态属性,静态方法,不能调用非静态结构
- 非静态代码块
- 内部可以有输出语句
- 随着对象的创建而执行
- 每创建一次就会被执行一次
- 作用:可以在创建对象时,对对象的属性进行初始化
封装
属性私有,get,set
继承
- 只支持单继承和多层继承
- 1个子类只能有1个父类
- 1个父类可以有多个子类
多态
父类的引用指向子类的对象
Person p1 = new Man();虚拟方法调用:当调用方法时,编译期,只能调用父类声明的方法。但在运行期,我们实际执行的时子类重写父类的方法。
总结:编译,看左边;运行,看右边(运行时行为)
作用:在方法上的形参使用父类,当调用方法时传入子类对象,就会是子类调用方法。
注意:对象的多态性只适用于方法,不适用于属性
向下转型:父类想转型为子类,需要加上强制转换(子类),但如果已经多态使用了向上转型,再转其他类型就会报错,如:
Person p2 = new Man(); Woman woman =(Woman)p2;就会报错ClassCastExceptioninstanceof:为了避免在向下转型时出现异常,我们在向下转型之前,先进行instanceof的判断,一旦为true,就进行向下转型,flase就不转型。
重写
- 子类不能重写父类声明为private权限的方法
抽象类
public abstract class test{}
抽象类是继承重写
抽象类不能实例化
abstract不能用来修饰:属性、构造器
不能用来修饰私有方法、静态方法、final方法
模板方法设计模式
- 在软件开发实现一个算法时,整体步骤很固定通用,这些步骤已经在父类写好了。某些部分易变,易变的部分可以抽象出来,给子类实现。
接口
先写extends,后写implements
和类是相同级别,如果父类和接口定义了相同变量(非方法,方法是谁重写用谁的,都没重写类优先),需要加前缀,
super/接口名.变量如果同时实现两个接口中的同名方法,则都重写,调用时
接口名.super.方法,没有重写就报错。接口中的对象也是final的不能修改。
jdk7及之前:只能定义全局常量和抽象方法
- 全局常量:
public static final,书写时可以省略 - 抽象方法:
public abstract
- 全局常量:
jdk8:除了定义全局常量和抽象方法意外,还可以定义静态方法、默认方法
- 静态方法只能通过接口调用
- 通过实现类的对象,可以调用接口中默认方法
- 如果实现类重写了接口中的默认方法,仍然调用的是重写后的方法(类优先原则)
接口中不能定义构造器,意味着接口不可以实例化
接口与接口间是继承,而且可以多继承
抽象类和接口有哪些异同
1.都不能实例化 2.实现的方式都体现了多态接口的应用:代理模式
创建代理对象,构造器中传入被代理对象,调用代理对象的方法,则会执行被代理对象方法和代理对象自带的方法
内部类
分类:成员内部类(静态、非静态) vs 局部内部类(方法内、代码块内、构造器内)
- 成员内部类:
- 作为外部类的成员
- 调用外部类的结构
- 可以被static修饰
- 可以被4种不同的权限修饰
- 作为一个类
- 类内可以定义属性方法构造器
- 可以被final修饰,表示此类不可被继承
- 可被abstract修饰
- 作为外部类的成员
- 创建静态成员内部类
Person.Dog dog = new Person.Dog(); - 创建非静态成员内部类
Person p = new Person(); Person.Bird bird = p.new Bird(); - 调用属性:
- 内部类属性:this.name
- 形参:name
- 外部类变量:外部类名.this.name
- 属性名不同可直接调用
常用类的使用
Object类的使用
final、finally、finalize的区别
final是关键字,标记在属性上,该属性就不会被改变;标记在方法上,该方法不会被重写,标记在类上,该类不会被继承 finally是在异常中,最后一定执行的语句块 finalize是垃圾回收的方法== 和 equals()的区别
==运算符 如果比较的是基本数据类型:比较两个变量保存数据是否相等 如果比较的是引用数据类型:比较两个变量的地址值是否相等,即引用的是不是同一个实体 equals()方法 只适用于引用数据类型:Object类中的equals方法:和==的作用是相同的,一样是比较地址值 其他类可以重写equals方法,来进行比较两个对象的实体内容是否相同//重写equals方法 public boolean equals(Object obj){ if(this == obj){//如果两个都指向一个对象,肯定相等 return true; } if(obj instanceof Person){//如果是一个类型,进行比较,不是直接返回false Person p1 = (Person) obj; return this.age == p1.age && this.name.equals(p1.age);//这里name是字符串,需要使用字符串重写的equals方法,否则还是比较的地址 }else{ return false; } }注意:使用equals方法时,最好先判断x.equals(y)的x是不是Null,如果是null会报空指针异常
toString()
在没有重写时,obj类中输出的是地址值,name@哈希值 重写之后,返回的是实体内容信息
单元测试方法的使用
- 此类中是public,此类提供公共的无参构造器
- 方法上@Test
包装类的使用
java提供8种基本数据类型对应的包装类,使得基本数据类型变量具有类的特征
基本数据类型—>包装类:
new Integer()包装类—>基本数据类型:
.xxxvalue()自动装箱:
int num1 = 1; Integer a1 = num1;,不需要new了自动拆箱:
Integer b1 = new Integer(); int num = b1;,不需要xxxvalue()了基本数据类型/包装类 —>String类型
方式1:连接运算:
String str1 = num1+"";方式2:调用String的valueOf(xxx)的方法:
String str2 = String.valueOf(num2);方式3:调用包装类的parseXXX()方法,
Integer.paseInt(str1);注意:这里如果转换不正确,会出现NumberFormatException,检查数据是否正确
main()方法的使用
- main()方法作为程序的入口
- main()方法也是一个普通的静态方法
- main()方法可以作为我们与控制台交互的方式 run configurations–arguments–program arguments–输入参数
String类
- 是一个final类,代表不可变的字符序列
- 当对字符串重新赋值时,会在内存区重新开辟一个空间进行赋值
- 当对现有的字符串进行连接操作时,也会在内存区重新开辟一个空间进行赋值
- 当调用String的repalce()方法修改指定内存或字符串时,也会在内存区重新开辟一个空间进行赋值
- 底层是数组
- String实现了Serializable接口:表示字符串是支持序列化的
- String实现了Comparable接口:表示String可以比较大小
- 每个字面量在内存中只会存在一个,如果
a = "123",b = "123",则这两个指向的是同一个地址
String对象的创建
String s1 = "123"String s2 = new String("123");
这两种情况有什么区别?
- 第一种情况,s1的数据声明在方法区的常量池中
- 第二种情况,s2保存的是地址值,数据在堆空间中开辟空间以后对应的地址值
- 两者不相等
- 第二种情况在内存中有两个对象:1个是堆空间中new结构,另外一个是char[]对应的常量池中的数据”123”
String对象之间的对比
String s1 = "hello";
String s2 = "world";
String s3 = "hello" + "world";
String s4 = "helloworld";
String s5 = s1 + s2;
String s6 = s1 + "world";
String final s7 = s1 + "world";//因为final之后是常量,在内存中是在常量池的位置
s3 == s4;//true
s3 == s5;//false
s3 == s6;//false
s3 == s7;//true
结论:
- 常量与常量之间的拼接,结果仍然在常量池,常量池中不会存在任何相同内容的常量
- 只要其中有一个是变量,结果都是在堆中
- 如果拼接的结果调用intern()方法,返回值就是在常量池中
String对象的值传递
public class StringTest{
String str = new String("good");
char[] ch = {'t'.'e'};
public void change(String str,char ch[]){//因为这里的形参是另一个对象,它指向了另一个字面量,并不会影响到原对象
str="test";
ch[0] = 'b';//形参是另一个对象,两个指向的都是同一个数组,改变数组就改变原值
}
main(){
StringTest ex = new StringTest();
ex.change(ex.str,ex.ch);
ex.str;//good
ex.ch;//be
}
}
String常用方法
| int length() | 返回字符串长度 |
|---|---|
| char charAt(int index) | 返回某索引处的字符(从0开始) |
| boolean isEmpty() | 判断是否为空字符串 |
| String toLowerCase() | 将所有字符转换为小写(不会影响原字符串) |
| String toUpperCase() | 将所有字符转换为大写 |
| String trim() | 取出首位空白 |
| boolean equals(Object obj) | 比较字符串内容是否相同 |
| boolean equalsIgnoreCase(String anotherString) | 忽略大小写比较内容 |
| int copareTo(String anotherString) | 比较两个字符串大小 |
| String substring(int beginIndex) | 将字符串从开始索引截取到最后,从0开始 |
| String substring(int beginIndex,int endIndex) | 左闭右开区间[)截取,从0开始 |
| 前后缀 | |
| boolean endsWith(String suffix) | 测试此字符串是否以指定后缀结束 |
| boolean startsWith(String prefix) | 测试此字符串是否以指定前缀开始 |
| boolean startsWith(String prefix,int toffset) | 测试此字符串从指定索引开始有指定字符串 |
| 查找 | |
| boolean contains(String str) | 判断是否包含字符串 |
| int indexOf(String str) | 返回指定字符串在此字符串第一次出现的索引 |
| int indexOf(String str,int fromIndex) | 返回指定字符串在此字符串第一次出现的索引,从索引处开始查找 |
| int lastIndexOf(String str) | 从右边返回指定字符串在此字符串第一次出现的索引 |
| int lastIndexOf(String str,int fromIndex) | 从右边返回指定字符串在此字符串第一次出现的索引,从索引处开始查找 |
| 注意 | indexOf和lastIndexOf没有找到返回的都是-1 |
| 替换 | |
| String replace(char old,char new) | 返回新字符串,将新字符替换旧字符 |
| String replace(String old,String new) | 返回新字符串,将新字符串替换旧字符串 |
| String replaceAll(regex正则,String new) | 返回新字符串,将新字符串替换全部的匹配正则的字符串 |
| String replaceFirst(regex正则,String new) | 返回新字符串,将新字符串替换第一个的匹配正则的字符串 |
| 匹配 | |
| boolean matches(String regex) | 告知此字符串是否匹配给定的正则表达式 |
| 切片 | |
| String[] split(String regex) | 根据给定正则表达式的匹配拆分此字符串 |
| String[] split(String regex,int limit) | 根据匹配给定的正则表达式来拆分此字符串,最多不超过限制的个数 |
String的类型转换
与基本类型转换
基本数据类型/包装类 —>String类型
- 方式1:连接运算:
String str1 = num1+""; - 方式2:调用String的calueOf(xxx)的方法:
String str2 = String.valueOf(num2);
String类型 —>基本数据类型/包装类
- 调用包装类的parseXXX()方法,
Integer.paseInt(str1);
与char类型转换
String —> char[]
- 调用String的toCharArray()
char[] —> String
- 调用String的构造器
与byte类型转换
String —> byte[]
- 调用String的getBytes[]
- 也可以指定编码的字符集:getBytes[指定字符集”gbk”]
char[] —> String
- 调用String的构造器(默认使用默认的解码)
- 出现乱码是因为编码和解码不一致
StringBuffer类
String、StringBuffer、StringBuilder三者的异同
String:不可变的字符序列;底层使用char[]数组进行保存
StringBuffer:可变的字符序列:线程安全的,效率低;底层使用char[]数组进行保存
StringBuilder:可变的字符序列:线程不安全的,效率高;底层使用char[]数组进行保存
效率对比:StringBuilder > StringBuffer > String
源码分析:
问题1:
System.out.println(sb.length())长度为0原因1:虽然StringBuffer在底层为我们创建了一个长度为16的char数组,但在没有给StringBuffer赋值时,输出的长度自然是0,是按赋值的长度输出的
问题2:扩容问题,如果在添加数据到底层数组装不下,即超过16时,底层为我们自动扩容。
原因2:默认情况下,扩容为原来容量的2倍+2,同时将数组的元素复制到新数组中
指导意见:开发时最好使用StringBuffer(int capacity)或StringBuilder(int capacity)。参数就是我们指定的长度,避免经常扩容
小问题:
public void test(){
String str = null;
StringBuffer sb = new StringBuffer();
sb.append(str);//底层调用的是拼接字符串
sb.length()//4
sb//"null"
StringBuffer sb1 = new StringBuffer(str);//抛异常,NullPointerException。底层调用的是str.length(),空指针
}
StringBuffer常用的方法
| StringBuffer append(xxx) | 增:提供了很多append方法,用于进行字符串拼接 |
|---|---|
| StringBuffer delete(int start,int end) | 删:删除指定位置的内容 |
| StringBuffer replace(int start,int end,String str) | 改:把[start,end)位置替换为tr |
| StringBuffer insert(int offset,xxx) | 插:在指定位置插入xxx |
| StringBuffer reverse() | 把当前字符序列逆转 |
| int indexOf(String str) | 返回指定字符串在此字符串第一次出现的索引 |
| String substring(int start,int end) | 将字符串从开始索引截取到结束,从0开始 |
| int length() | 长度:返回长度 |
| char charAt(int n) | 查:返回某索引处的字符(从0开始) |
| void setCharAt(int n,char ch) | 设置某索引处的字符 |
遍历:for(sb.length())+charAt() / toString()
String算法题
//将字符串中指定位置进行反转
public String reverse(String str,int startIndex,int endIndex){
if(str != null){
//第一部分
String reverseStr = str.substring(0,startIndex);
//第二部分
for(int i = endIndex;i >= startIndex;i--){
reverseStr += str.charAt(i);
}
//第三部分
reverseStr += str.substring(endIndex + 1);
return reverseStr;
}
return null;
}
//方式2:使用StringBuffer/StringBuilder替换String
public String reverse2 (String str,int startIndex,int endIndex){
if(str != null){
StringBuffer sb = new StringBuffer(str.length());
//第1部分
sb.append(str.substring(0,startIndex));
//第2部分
for(int i = endIndex;i>=startIndex;i--){
sb.append(str.charAt(i));
}
//第3部分
sb.append(str.substring(endIndex+1));
return sb.toString();
}
return null;
}
//获取一个字符串在另一个字符串中出现的次数
public int getCount(String mainStr,String subStr){
int count = 0;
int mainLength = mainStr.length();
int subLength = subStr.length();
int index = 0;
if(mainLength >= subLength){
while((index = mainStr.indexOf(subStr,index))!=-1){//从index处开始查找,返回索引,第一次为0,之后依次从索引+sublength处开始继续查找
count ++ ;
index += subLength;
}
}else{
return 0;
}
}
时间类
时间戳
System.currentTimeMillis():1970年1月1日0点到现在的毫秒值
Date类
Util.Date
| Date()空参构造器 | |
|---|---|
| toString() | 显示当前年月日时分秒 |
| getTime() | 获取当前Date对象对电影的毫秒数 |
| Date(创建指定毫秒数的Date对象) | |
Util.Date与Sql.Date转换
Date date = new Date();
java.sql.Date date2 = new java.sql.Date(date.getTime());
SimpleDateFormat日期格式化类
因为是非静态的类,需要实例化对象才能使用SimpleDateFormat sdf = new SimpleDateFormat();
实例化
SimpleDateFormat sdf = new SimpleDateFormat(); //参数可以是:yyyy-MM-dd hh:mm:ss格式化:日期 —> 字符串
Date date = new Date(); String format = sdf.format(date);解析:字符串 —> 日期
String str = "20-10-04 上午11:11";//解析的格式必须和实例化的格式一样 Date date1 = sdf.parse(str);
Calendar日历类
因为是非静态的类,需要实例化对象才能使用
实例化
//方式1:创建其子类(GregorianCalendar)的对象 //方式2:带哦用其静态方法getInstance() Calendar calendar = Calendar.getInstance();
常用方法
get():获取相关信息,calendar.get(Calendar.DAY_OF_MONTH);
set():改变相关信息,将calendar对象的值修改,可变性。calendar.set(Calendar.DAY_OF_MONTH,22);
add():修改信息,calendar.add(Calendar.DAY_OF_MONTH,-3)
getTime():日历类 —> Date,Date date = calendar.getTime();
setTime():Date —> 日历类,calendar.setTime(date);
注意:月份是从0开始
JDK8新时间类
LocalDate,LocalTime,LocalDateTime(使用频率较高)
| now() | 获取当前日期/时间/日期+时间 | LocalDate.now() |
|---|---|---|
| of() | 设置指定年月日,时分秒 | LocalDate.of(2020.10.4) |
| getxxx() | 获取时间 | LocalDate.getMonth() |
| withxxx() | 设置相关属性,有返回值,体现不可变性 | localDate.withDayOfMonth(22) |
| plusxxx() | 增加相关属性,有返回值,体现不可变性 | localDate.plusMonths(3) |
| minusxxx() | 减少相关属性,有返回值,体现不可变性 | localDate.minusMonths(3) |
Java比较器
Comparable接口的使用举例:
- String、包装类等实现了Comparable接口,重写了compareTo(obj)方法,给出了比较对象的逻辑,他们是进行了从小到大的排列
- 重写compareTo(obj)的规则
- 如果当前对象this大于形参对象obj,则返回正整数
- 如果当前对象this小于形参对象obj,则返回负整数
- 如果当前对象this等于形参对象obj,则返回零
总结:Comparable接口与Comparator的使用的对比
- Comparable接口的方式一旦指定,保证Comparable接口实现类的对象在任何位置都可以比较大小
- Comparator接口属于临时性的比较,什么时候需要就创建一个实现类。
自定义实现Comparable自然排序
自定义类(bean)实现Comparable接口
重写里面的compareTo()方法,就是排序的逻辑
public int compareTo(Object o){ if(o instanceof foods){ Foods foods = (Foods)o; if(this.price > foods.price){//如果当前对象this大于形参对象obj,则返回正整数 return 1; }else if(this.price < foods.price){ return -1; }else{ return 0; //return this.name.compareTo(foos.name) 二级排序(实现的方式和上述效果一样) } } throw new RuntimeException("传输的数据类型不一致") }调用
Foods[] arr = new Foods[5]; arr[0] = new Foods("aaa",34); arr[1] = new Foods("bbb",12); Arrays.sort(arr);
实现Comparator定制排序
使用匿名实现类Comparator
Foods[] arr = new Foods[5]; arr[0] = new Foods("aaa",34); arr[1] = new Foods("bbb",12); Arrays.sort(arr,new Comparator(){ public int compare(Object o1,Object o2){ if(o1 instanceof String && o2 instanceof String){ String s1 = (String) o1; String s2 = (String) o2; return -s1.compareTo(s2);//使用compareble实现的方法从小到大排列的反义词,即从大到小排列 } //return 0; throw new RuntimeException("输入的数据类型不一样") } }); System.out.println(Arrays.toString(arr));
System类
构造器是私有的
内部成员变量、方法都是stsatic的
成员变量:in,out,err
成员方法
long currentTimeMillis() 返回当前计算机时间:1970.1.1毫秒数 void exit(int status) 0:退出,非0:异常退出。用于图形化界面退出 void gc() 请求系统进行垃圾回收,并不一定立即回收 String getProperty(String key) 获取系统属性值
Math类
都是静态方法
方法参数和返回值一般都是double类型
abs 绝对值 sqrt 平方根 pow(double a,double b) a的b次幂 log 自然对数 exp e为底的值数 max/min(double a,double b) random() 返回【0.0-1.0)的随机数 公式:取规定[a,b]的整数 (int)(Math.random()*(b-a+1)+a) long round(double a) double类型数据a转换为Long型(四舍五入)
枚举类
- 类的对象只有有限个,确定的
- 当需要定义一组常量,建议使用枚举类
- 如果枚举类中只有一个对象,可以作为单例模式的实现方式
- 调用:类.枚举属性
使用enum关键词创建枚举类
- 规则
- 使用enum关键字
- 先提供当前枚举类对象,再声明属性
- 多个对象之间用,隔开 末尾对象用;结束
- 不需要重写toString方法
- 没有Set方法
enum Season1{
//提供当前枚举类对象,多个对象之间用,隔开 末尾对象用;结束
SPRING("春天"),
SUMMER("夏天");
//声明Season对象的属性:private final修饰
private final String seasonName;
//私有化构造器,并给对象属性赋值
private Srason1(String seasonName){
this.seasonName = seasonName;
}
//get方法
}
| values() | 返回枚举类的对象数组,方便遍历所有枚举值 |
|---|---|
| valueOf(String str) | 返回枚举类中对应对象名是objName的对象,没有找到会报IllegalArgumentException |
| toString() | 返回当前枚举类对象的名称 |
实现接口
方式一:调用任何枚举类型都会调用该方法
- 实现接口,重写方法
方式二:不同枚举类型调用不同方法
SPRING("春天"){
@Override
public void show(){
System.out.println("春天你好")
}
},
SUMMER("夏天"){
@Override
public void show(){
System.out.println("夏天你好")
}
};
注解
jdk5.0新增功能
- 生成文档相关注解
- 在编译时进行格式检查(重写、过时、抑制警告)
- 跟踪代码依赖性,实现代替配置文件功能
| @SuppressWarnings | 抑制编译器警告 |
|---|---|
自定义Annotation
- 规则
- 使用@interface关键字
- 内部定义成员,通常使用value表示
- 可以指定成员的默认值,使用defalut定义
- 如果自定义注解没有成员,表明是一个标识作用
- 如果有成员,在使用时需要指定value值
元注解
对现有的注解进行解释说明的注解
- Retention:指定所修饰的注解生命周期:SOURCE编译前\CLASS编译后(默认行为)\RUNTIME运行后
- 只有声明为RUNTIME生命周期的注解,才能通过反射来获取
- Target:用于指定被修饰的注解能用于修饰哪些程序元素
- Documented:所修饰的注解在被javadoc解析时,保留下来
- Inherited:被其修饰的注解将具有继承性
JDK8新特性
- 可重复注解:
- 在注解类上声明@Repeatable,成员值为MyAnnotation.class
- 在MyAnnotation的Target和Retention和MyAnnotations,Inherited相同
- 新类型注解(Target)
- ElementType.TYPE_PARAMETER 表示该注解能写在类型变量的声明语句中
- ElementType.TYPE_USE 标识该注解能写在使用类型的任何语句中
集合框架
概述
数组在存储多个数据的特点
- 一旦初始化之后,长度和元素的类型都已经确定
数组在存储多个数据的缺点
- 初始化之后,长度不能修改
- 数组提供的方法有限,对增删插操作非常不便,效率不高
- 获取数组中元素的个数,数组没有现成的方法和属性可用
- 数组存储的特点:有序、可重复。对无序,不可重复的需求不能满足
体系
- Collection接口:单列数据
- List:元素有序、可重复(“动态”数组)
- Set:元素无序,不可重复
- Map接口:双列数据
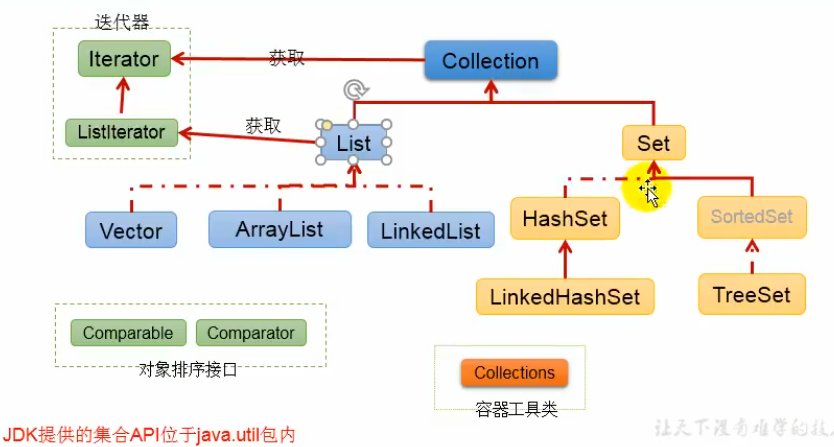
实线:继承关系,虚线:实现关系
Collection
因为是接口,需要创建其实现类调用这些方法api
注意:对实现类对象中添加数据obj时,要求对obj所在类重写equals()方法
| add(Object obj) | 增加元素到集合中 |
|---|---|
| addAll(List l) | 将集合中的元素添加到当前集合中 |
| size() | 获取增减的元素个数 |
| boolean isEmpty() | 判断当前集合是否为空 |
| clear() | 清空集合元素,并不是空指针 |
| boolean contains(Object obj) | 判断集合中是否存在该元素(查的是内容,判断时会调用obj对象的equals()方法) |
| boolean containsAll(Collection c) | 判断形参集合中所有元素是否都存在于当前集合中 |
| remove(Object obj) | 移除数据,(同样底层调用obj对象的equals()方法) |
| removeAll(Collection c) | 从当前集合中移除c集合中的元素 |
| Collection retainAll(Collection c) | 获取当前集合和c集合的交集,并返回集合 |
| equals(Object o) | 比较两个集合中每个对象是否相同 |
| hashCode() | 返回当前对象的哈希值 |
| Object[] toArray() | 集合 —> 数组 |
| Arrays.asList(Array a[]) | 数组 —> 集合,注意:Arrays.asList(new int[]{1,2})返回的是一个地址,数组个数也是1,需要将int换成Integer |
| iterator iterator() | 迭代器,返回一个iteractor接口的实例,用于遍历集合元素 |
Iterator迭代器
是一个接口,需要集合调用iterator()方法来获得迭代器接口实例。
它只是一个迭代器,并不是容器,类似指针,不会创建新的集合
每次调用iterator()方法都会得到一个全新的迭代器对象
next()方法做了两件事:1.指针下移,2.将下移之后指向的元素返回
| Object next() | 获取集合中的一个元素(1.指针下移,2.将下移之后指向的元素返回) |
|---|---|
| boolean hasNext() | 判断是否还有下一个元素 |
| remove() | 移除迭代器指针指向的元素 |
//遍历集合
Collection col1 = new ArrayList();
Iterator it =col1.iterator();//获得迭代器实例
while(it.hasNext()){
//如果还有元素,则进入循环
System.out.println(it.next());
}
//错误方式1:跳着输出
while((it.next())!=null){//下移了一次
System.out.println(it.next());//又下移一次,当最后一次会出现没有找到数据情况
}
//错误方式2:新迭代器,死循环
while(col1.iterator().hasNext()){
System.out.println(col1.iterator().next());//创建新的迭代器对象,只会读出第一行数据
}
//remove()
Collection col1 = new ArrayList();
Iterator it =col1.iterator();//获得迭代器实例
while(it.hasNext()){
if("Tom".equals(it.next())){//判断该值是否为tom,小细节:把字符串放在前面,不用对象放前边可以防止空指针异常,代码健壮性更好
it.remove();
}
}
注意:在还没有next()之前,不要调用remove(),会报IllegalStateException异常
增强for循环(for each)
格式:for(集合元素的类型 局部变量:集合对象)
本质也是迭代器
for(Object obj : col1){
System.out.println(obj);
}
注意:使用for each循环给数组赋值时,不会将原数组的值相等
List
- 元素有序、可重复
ArrayList、LinkedList、Vector三者的异同
- 同:三个类都实现了List接口,存储数据的特点相同:存储有序、可重复
不同:
- ArrayList:作为List接口主要实现类;线程不安全的,效率高;底层使用Object[]数组存储
- LinkedList:对于频繁插入、删除操作,使用此类效率比Arraylist高;底层使用双向链表存储
- Vector:作为List接口的古老实现类;线程安全的,效率低;底层使用Object[] 数组存储(扩容2倍)
ArrayList源码分析
jdk7情况下
ArrayList list = new ArrayList();//底层创建了长度为10的Object[]数组
list.add(1);//elementData[0] = new Integer(1);
...//如果此次添加导致底层数组容量不够,则扩容
//默认情况下,扩容为原来的容量1.5倍,同时需要将原来的数组复制到新数组中
结论
- 初始化长度为10,容量不够则扩容1.5倍
- 开发中建议使用带参构造器,将长度直接写上去,避免扩容,
ArrayList list = new ArrayList(int xxx)
jdk8之后
ArrayList list = new ArrayList();//底层Object[] 初始化为{},并没有创建长度
list.add(123);//第一次调用add()时,底层才创建了长度为10的数组,并将数据添加到数组当中
...//后续扩容问题跟jdk7无异
结论:
- 初始化长度为0,只有在第一次增加操作时,数组才初始化为10
LinkedList源码分析
LinkedList list = new LinkedList();//内部声明了Node类型的first和last属性,默认值为null
list.add(123);//将123封装进node中,创建了Node对象
//其中,Node定义为:体现了LinkedList的双向链表的说法
List常用方法
| void add(int index,Object obj) | 在index位置插入元素 |
|---|---|
| boolean addAll(int index,Collection c) | 从Index位置开始将c中所有元素添加进来 |
| Object get(int index) | 获取指定Index位置的元素(从0开始) |
| int indexOf(Object obj) | 返回Obj在集合中首次出现的位置 |
| int lastIndexOf(Object obj) | 返回Obj在集合中最后一次出现的位置 |
| Object remove(int index) | 移除指定Index位置的元素,并返回此元素 |
| Object set(int index,Object obj) | 设置指定index位置的元素为obj |
| List subList(int fromIndex,int toIndex) | 返回从fromIndex到toIndex位置的子集合 |
总结:
增:add(Object obj)
删:remove(int index)/remove(Object),默认是索引,如果想删元素需要装箱new Integer(value)
改:set(int index,Object o)
查:get(int index)
插:add(int index,Object o)
遍历:
- Iterator 迭代器
- 增强for
- 普通循环
Set
- 无序的,不可重复的
- 无序性:不等于随机性。存储的数据在底层数组中,并非按照数组索引的顺序增加,而是通过数据的哈希值决定的
- 不可重复性:保证添加的元素按照equals()判断时,不能返回true。即:相同的元素只能添加一个
- Set没有额外的方法,都是用的Collection中的方法
HashSet、LinkedHashSet、TreeSet之间的异同
- HashSet:作为Set接口的主要实现类;线程不安全的;可以存储Null值
- LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照插入的顺序进行排序,对于频繁遍历的操作,它的效率比HashSet高一些
- TreeSet:可以按照指定属性,进行排序
HashSet底层分析
底层:数组+单向链表
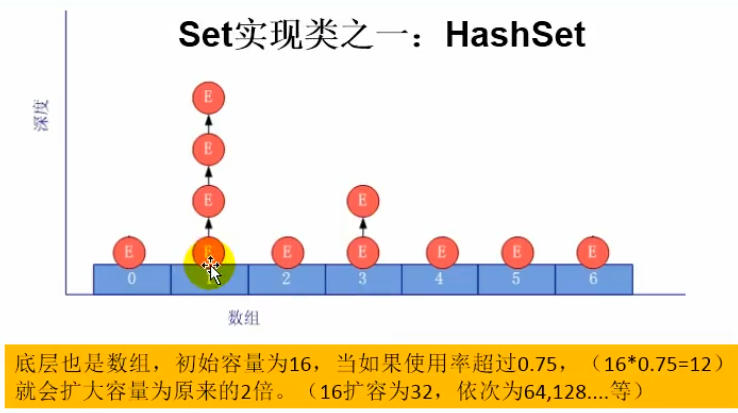
增加元素的过程:以HashSet为例
我们向HashSet中添加元素a,首先会调用元素a所在类的**hashCode()**方法,计算出元素a的哈希值
此哈希值接着通过某种算法计算出在hashSet底层数组中的存放位置(索引位置),
判断数组此位置上是否有元素
如果没有元素,则添加成功—-情况1
如果位置上有其他元素(或以链表存在多个元素),则比较元素a和所在位置元素的哈希值:
如果哈希值不相等,则添加成功—-情况2
如果哈希相等,则进一步调用元素a所在类的equals()方法:
equals()返回为true,证明两个值相同,则添加失败
equals()返回为false,则元素a添加成功—-情况3
- 对于情况2,3:元素a于该索引位置上的其他元素是以单向链表的形式存储的
- jdk7:新元素放在数组中,指向旧元素
- jdk8:旧元素仍然在数组中,指向新元素
- 总结:七上八下
要求:
- 向Set中添加的数据,其所在类一定要重写hashCode()和equals()方法
- 重写的hashCode()和equals()尽可能保持一致性:相同内容的对象,哈希值也相同
- 一般直接用系统生成的就可以保证一致性
LinkedHashSet底层分析
作为HashSet的子类,在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据
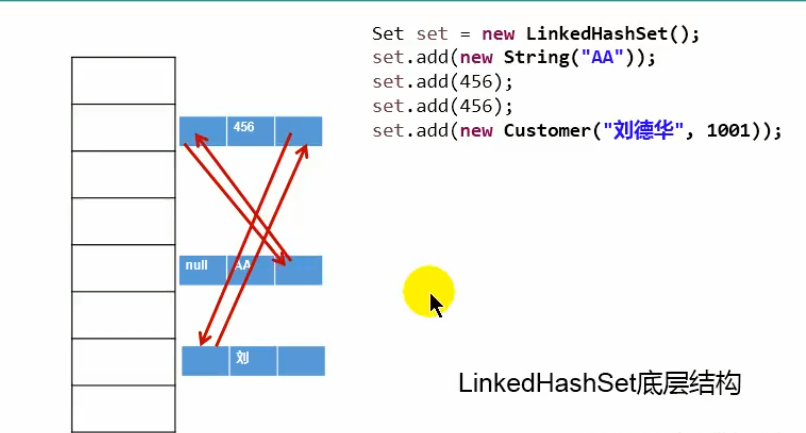
优点:对于频繁的遍历操作,LinkedHashSet效率高于HashSet
TreeSet底层分析
插入数据,要求是相同类的对象
两种排序方式:自然排序(数据对应类实现Comparable接口)和定制排序
自然排序中,比较两个对象是否相同的标准:compareTo()返回0(实现自然排序必须重写该方法),不再是equals(),即只按规则进行排序,不按内容(插入时规则相同,就不能插入)
public int compareTo(Object o){ if(o instanceof User){ User user = (User)o; int compare = -this.name.compareTo(user.name); if(compare != 0){//内容不相同 return compare;//返回正负值,来进行排序 }else{//内容相同,按下一个内容进行排序 return Integer.compare(this.age,user.age); } }else{ throw new RuntimeException("输入类型不匹配"); } }定制排序
Comparator com = new Comparator(){ @Override public int compare(Object o1,Object o2){ if(o1 instanceof User && o2 instanceof User){ User u1 = (User) o1; User u2 = (User) o2; return Integer.compare(u1.getAge(),u2.getAge()); }else{ throw new RuntimeException("输入的数据类型不匹配"); } } } TreeSet set = new TreeSet(com);//传入参则使用定制排序,否则使用自然排序
集合面试题
集合Collection中存储的如果是自定义类的对象,需要自定义类重写哪些方法?为什么?
equals()方法。 在调用contains()/remove()等方法时,都会调用equals方法 List:equals()方法 Set:(HashSet、LinkedHashSet为例):equals()、hashCode() (TreeSet为例):Comparable:compareTo(Object obj) Comparator:compare(Object o1,Object o2)ArrayList,LinkedList,Vector三者的相同点与不同点
相同:都实现于List接口,数据结构的特点相同:有序、可重复 不同: ArrayList:是最主要的实现类,底层是数组存储,线程不安全,效率高,底层数组扩容是以前的1.5倍 Vector:是比较古老的实现类,底层是数组存储,线程安全,效率较低,底层数组扩容是以前的2倍 LinkedList:底层是双向链表,插入、删除的效率高。 源码: ArrayList底层源码在jdk8之后有所改动,在jdk8之前,new一个ArrayList会创建一个长度为10的数组,之后的版本new只会创建一个空的数组,当第一次调用add()时,才会创建长度10的数组,并且库容都是1.5倍 LinkedList:内部声明的都是Node类型,不仅存有数据,还存有上一个node和下一个Node的数据。 Vector:底层也是数组,长度为10没有变动,扩容是2倍List和Set的区别
相同:都实现于Collection接口 不同: List:有序可重复 Set:无序不可重复List接口有哪些常用方法?
增:add(Object obj) 删:remove(Object obj)/remove(int index) 改:set(int index,Object obj) 查:get(int index) 插:add(int index,Object obj) 长度:size()//元素的个数 遍历:iterator,foreach,普通for(有索引,Set和Colleciton不可以使用)如何使用Iterator和增强for循环遍历list
Iterator it = list1.iterator(); while(it.hasNext()){ System.out.println(it.next()); } for(Object obj : list1){ System.out.println(obj); }Set存储数据的特点是什么?常见的实现类有什么?说明一下彼此的特点
特点:无序不可重复 实现类:HashSet、LinkedHashSet、TreeSet HashSet:是Set的主要实现类,线程不安全,可以存储Null值 LinkedHashSet:是HashSet的主要实现类,在内部存储时会记录插入的顺序,遍历时可以按照插入顺序进行排序,遍历时效率高一些 TreeSet:可以按照指定的属性进行排序判断结果
public void test(){ HashSet set = new HashSet(); Person p1 = new Person("1001","aa"); Person p2 = new Person("1002","bb"); set.add(p1); set.add(p2); System.out.println(set);//2个 p1.name = "cc";//此时1001cc仍然保存在1001aa的位置 set.remove(p1);//此时找的是1001cc的哈希值,但更改后的cc仍然在aa的位置,故没有删除 System.out.println(set);//2个 set.add(new Person(1001,"cc"));//此时找的是1001cc的哈希值,故插入成功 System.out.println(set);//3个,bb,cc,cc set.add(new Person(1001,"aa"));//此时找的是1001aa的哈希值,虽然位置上有cc,但是equals()方法比较两个不一样,故用链表存储成功 System.out.println(set);//4个,bb, cc,aa ,cc }
Map

双列数据,存储Key-value对的数据
不同实现类的区别
HashMap:作为Map的主要实现类;线程不安全的,效率高;存储Null
–LinkedHashMap:保证在添加Map元素时,可以按照添加的顺序实现遍历(在原有HashMap结构上,增加了一对指针,指向前一个和后一个元素),对于频繁的遍历操作,此类效率高
TreeMap:保证按照添加的Key-value进行排序,按照(key)来排序。此时考虑key的自然排序和定制排序 。底层使用的红黑树
Hashtable:作为古老的实现类;线程安全的,效率低;不能存储null
–Properties:常用来处理配置文件,key-value都是String类型
HashMap的底层:数组+链表(jdk7及以前)。数组+链表+红黑树(jdk8)
面试题:
- HashMap的底层实现原理?
- HashMap和Hashtable的异同?
- CurrentHashMap与Hashtable的异同?
Map结构的理解

key:无序的、不可重复的,使用Set存储所有的Key —> key 所在类要重写equals()和hashCode()
value:无序的、可重复的,使用Collection存储所有的value —>value所在的类药重写equals()
entry:就是一个键值对,无序的、不可重复的,使用Set存储所有的entry
HashMap的底层实现原理?
JDK7为例
HashMap map = new HashMap();
在实例化以后,底层创建了长度为16的一维数组Entry[] table
map.put(key1,value1);
首先,调用key1所在类的hashCode()计算key1的哈希值,此哈希值经过某种算法之后,得到Entry数组所在的位置
如果该位置数据为空,则key1-value1添加成功。—情况1
如果该位置数据不为空(意味着此位置上存在一个或多个数据(以链表的形式存在)),比较Key1和一个或多个数据的哈希值:
如果key1的哈希值和其他数据哈希值不相同,则key1-value1添加成功。—情况2
如果key1的哈希值和其他数据哈希值相同,则继续**比较equals(key)**,
如果equals返回为false(不相同):则添加成功。—情况3
如果equals返回为true:使用value1替换原有value值(修改的作用)。
补充:情况2,3存储的数据是以链表的形式存储。
如果涉及到扩容问题,当超出临界值(且要存放的位置有值)时,扩容为原来容量的2倍,则并将原有数据复制过来。如果到临界值,要存放的位置无值,则继续往后加值。
JDK8相较于7在底层实现方面的不同
new HashMap():底层没有创建一个长度为16的数组
Jdk8 底层的数组是:Node[],而非Entry[]
首次调用put()方法时,底层创建长度为16的数组
jdk7底层结构只有:数组+链表。Jdk8中底层结构:数组+链表+红黑树
当数组某个索引位置上的元素以链表形式存在的数据个数>8,且数组长度>64时,
此时该索引位置上的所有数据改为使用红黑树存储
DEFAULT_INITIA_CAPACITY:HashMap的默认容量:16
DEFAULT_LOAD_FACTOR:HashMap的默认加载因子:0.75(小会导致数据碰撞小,数组空间经常会扩容,链表短;大会导致数据碰撞高,链表长,影响查询和插入)决定了HashMap的数据密度
threshold:扩容的临界值,容量 * 加载因子:16*0.75=12(达到该临界值(且后续有值)就会扩容)
TREEIFY_THRESHOLD:链表长度大于该默认值,转化为红黑树:8
MIN_TREEIFY_CAPACITY:Node被树化时最小的hash表容量:64
LinkedHashMap底层实现原理(了解)
多了before和after来记录存储顺序

Map接口的方法
| 增加、删除、修改 | |
|---|---|
| Object put(Object key,Object value) | 添/改:将指定Key-value增加(或修改)到map中 |
| void putAll(Map m) | 将m中的所有key-value存放到当前Map中 |
| Object remove(Object key) | 删:移除指定key的Key-value,并返回value |
| void clear() | 清空当前Map中的所有数据 |
| 元素查询 | |
| Object get(Object key) | 查:获取指定key对应的value |
| boolean containsKey(Object key) | 是否包含指定的key |
| boolean containsValue(Object value) | 是否包含指定的value |
| int size() | 长度:返回map中Key-value的个数 |
| boolean isEmpty() | 判断当前Map是否为空 |
| boolean equals(Object obj) | 判断当前map和参数对象obj是否相等(也得是Map) |
| 元视图操作 | 遍历: |
| Set keySet() | 返回所有Key构成的Set集合 |
| Collection values() | 返回所有value构成的collection集合 |
| Set entrySet() | 返回所有key-value构成的Set集合 |
//遍历entry的set集合,方式1
Set entrySet = map.entrySet();
Iterator it = entrySet.iterator();
while(it.hasNext()){
Object obj = it.next();
//entrySet集合中的的元素都是entry
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey()+":"+entry.getValue());
}
//方式2
Set set = map.keySet();
Iterator it = set.iterator();
while(it.hasNext()){
Object key = it.next();
Object value = map.get(key);
System.out.println(key+":"+value);
}
TreeMap的使用
向TreeMap中添加key-value,要求key必须是由同一类创建的对象
因为要按照key进行排序:自然排序、定制排序
//自然排序,key所在类必须实现comparable接口 public void test(){ TreeMap map = new TreeMap(); User u1 = new User("Tom",23); User u2 = new User("Jerry",13); map.put(u1,98); map.put(u2.99); //遍历 Set entrySet = map.entrySet(); Iterator it = entrySet.iterator(); while(it.hasNext()){ Object obj = it.next(); //entrySet集合中的的元素都是entry Map.Entry entry = (Map.Entry) obj; System.out.println(entry.getKey()+":"+entry.getValue()); } } //定制排序 public void test1(){ Tree map = new TreeMap(new Comparator(){ @Override public int compare(Object o1,Object o2){ if(o1 instanceof User && o2 instanceof User){ User u1 = (User) o1; User u2 = (User) o2; return Integer.compare(u1.getAge(),u2.getAge());//按照年龄从小到大排序 } throw new RuntimeException("输入的类型不匹配"); } }); //后面都一样 }
面试题
Map存储数据的特点是什么?并指明key、value、entry存储数据的特点
双列数据,存储key-value数据 key:无序的、不可重复的---Set value:无序的、可重复的---collection key-value:无序、不可重复---Set描述HashMap的底层实现原理
在第一次初始化时,并不会常见出长度为16的node数组,只有在第一次调用Put方法,才会真正创建出长度为16的数组。 调用put方法存key-value时,会将key调用hashCode()方法计算出哈希值,再经过某种算法计算出存储在node数组中的位置。 如果该位置没有值,则添加成功----情况1 如果该位置有值(有可能是一个或多个数据组成的链表),则比较哈希值 如果哈希值不同,则添加成功,通过链表的方式存储在数组中----情况2 如果哈希值相同,则调用key所在类的equals()方法进行比较 如果返回为false,则添加成功----情况3 如果返回为true,则将新的value值替换为旧value值 HashMap的底层存储结构是:数组+链表+红黑树 当数组上的某个位置上的链表长度超过8且数组的总长度大于64,则将该链表变为红黑树存储 当涉及到数组扩容问题时,HashMap底层有临界值,当要存储的数据超过临界值(且存储的位置有值时),会将数组扩容为原来的2倍,并将原来的数据复制进新的数组当中。Map中常用实现类有哪些?各自有什么特点?
HashMap:是Map的主要实现类,线程不安全的,效率高,可以存储Null值 LinkedHashMap:保证在存储key-value时,可以根据添加的顺序进行遍历,在HashMap的基础上,增加了两个指针,分别指向前后数据,在频繁遍历时效率更高。 TreeMap:保证在存储key-value时,根据key进行排序,具体排序规则根据Key的自然排序和定制排序 。底层使用的是红黑树 Hashtable:是Map的古老实现类,线程安全,效率低,不能存储Null值 Properties:存储方式也是key-value,键值对都是String类型,用于配置文件LinkedHashMap的底层实现原理
底层和HashMap的机构相同,因为LinkedHashMap继承了HashMap,区别在于LinkedHashMap内部提供了Entry,替换了Node类型,其中增加了before和after用于存储上一个和下一个数据,更有利于遍历。如何遍历map,代码实现
Set set = map.keySet(); Iterator it =set.iterator(); while(it.hasNext()){ Object key = it.next(); Object value = map.get(key); System.out.println(key+":"+value); }Collection和Collections的区别?
Collection是一个存储单列数据的接口,内部包括List和Set Collections是操作Collection和Map的常用工具类TreeMap的使用?
向TreeMap中添加数据,要求key的类型保持一致 因为要按照key进行排序:自然排序、定制排序
Collections工具类
面试题:Collection和Collections的区别?
Collection是一个存放单列数据的接口,而Collections是操作Collection、Map的工具类
常用方法
| 排序 | |
|---|---|
| reverse(List) | 反转List中元素的顺序 |
| shuffle(List) | 对List集合元素进行随机排序 |
| sort(List) | 根据元素的自然顺序对指定List集合元素按升序排序 |
| sort(List,Comparator) | 根据指定Comparator产生的顺序对List集合元素进行排序 |
| swap(List,int index1,index2) | 将指定List集合中的两个元素进行交换 |
| 查找、替换 | |
| Object max(Collection) | 根据元素自然排序,返回最大元素 |
| Object max(Collection,Comparator) | 根据Comparator指定的顺序,返回给定集合的最大元素 |
| Object min(Collection) | 最小 |
| Object min(Collection,Comparator) | 最小 |
| int frequency(Collection,Object) | 返回指定集合指定元素的出现次数 |
| void copy(List dest,List src) | 将src中的内容赋值到dest中 |
| boolean replaceAll(List,Object old,Object new) | 把list中的旧值换成新值 |
//copy()方法的问题
//错误示范:
List dest = new ArrayList();
Collections.copy(dest,list);
//正确操作
List dest = Arrays.asList(new Object[list.size()]);
Collections.copy(dest,list);
同步控制
Collections类中提供了多个**synchronizedXxx()**方法,可以让指定集合包装成线程同步的集合。
ArrayList list = new ArrayList(); List list=Collections.synchronizedList(list);
数据结构:
顺序表(Array,ArrayList)
特点:
- 使用连续分配的内存空间
- 一次申请一大段连续的空间,需要实现声明最大可能要占用的固定内存空间
优点:
设计简单,读取与修改表中任意一个元素的时间都是固定的
缺点:
- 容易造成内存浪费
- 删除或插入需要移动大量数据
链表(LinkedList)
特点:
- 使用不连续的内存空间
- 不需要提前声明好指定大小的内存空间
优点:
- 充分节省内存空间
- 数据的插入与删除方便,不需要移动大量数据
缺点:
- 设计麻烦
- 查找数据必须按照顺序找到该数据为止
泛型
泛型不能是基本数据类型,需要使用其包装类
在jdk5.0时,集合接口和集合类都修改为带泛型结构
在实例化集合时,可以指明具体泛型结构
指明之后,集合类或接口中凡是定义类或接口时,内部结构使用到泛型都和定义的相同
如果实例化时,没有指明泛型的类型,默认为Object类型
jdk7:类型推断
HashMap<User> map = new HashMap<>();
//指明泛型的comparable接口
public User implements Comparable<User>{//指定泛型
@Override
public int compareTo(User u){//因为指明了泛型,形参直接改变,不需要判断类型了
return this.name.compareTo(u.name);
}
}
自定义泛型类
定义泛型类,建议在实例化时指明类的泛型
如果没有指明,则认为泛型类型为Object类型
构造器不需要加<>,但是实例化需要加
public Order<T>{//定义泛型类 T orderT; public Order(T orderT){ this.orderT = orderT; } } public void test(){ Order<String> order = new Order<>("123");//指明泛型类型,则参数就是什么类型 }子类继承父类时声明泛型,则泛型就是什么类型
public class OrderChildren extends Order<Integer>{ } public void test(){ OrderChildren child = new OrderChildren(123);//因为继承父类指定泛型,则参数就是什么类型 //注意:子类只是一个普通类,不需要加<> }定义泛型类,子类继承父类时也没有声明泛型,建议在实例化时指明类的泛型
public class OrderChildren<T> extends Order<T>{ } public void test(){ OrderChildren<String> child = new OrderChildren<>("123");//泛型类指明类型,则参数就是什么类型 }
泛型在继承方面的体现:
类A是类B的父类,G和G二者不具备子父类关系:
List<Object> list1; List<String> list2,list2不能赋值给List1
类A是类B的符类,A
,B 可以赋值 List<String> list1; ArrayList<String> list2,可以赋值
通配符:类A是类B的父类,G和G二者不具备子父类关系,G<?>是其父类,可以赋值
添加:对于List<?>不能向其内部添加数据
获取:允许读取数据,读取的数据类型为Object
有限制的通配符:
List<? extends Person> list1 = null;//泛型是person子类 List<? super Person> list2 = null;//泛型是person父类 List<Student> list3 = null; List<Person> list4 = null; List<Object> list5 = null; list1 = list3; list1 = list4; list1 = list5;//报错,extend表示是其子类 list2 = list3;//报错,super表示是其父类 //获取值 Student s = list1.get(0);//报错,最小为Person Object o = list2.get(0);//正确,最小为object
自定义泛型方法
泛型方法的泛型和泛型类的泛型没有关系,换句话说泛型方法还可以在普通类中声明
- 静态方法不能使用类的泛型
- 泛型方法,可以声明为静态。原因:泛型参数是在调用方法时确定的,并非实例化时确定
public class Order<T>{
//泛型类是T,泛型方法是E,没有任何关系
public <E> List<E> copy(E[] arr){
ArrayList<E> list = new ArrayList<>();
for(E e: arr){
list.add(e);
}
}
}
public void test(){
Order<String> order = new Order<>();
Integer[] arr = new Integer[]{1,2};
List<Integer> list= order.copy(arr);//泛型方法的泛型取决于传入的参数,与实例化无关
System.out.println(list);
}
面试题
如何遍历带泛型的key,value,map
//遍历key Map<String,Integer> map = new HashMap<>(); Set<String> keys = map.keySet(); for(String key:keys){ System.out.println(key); } //遍历value Map<String,Integer> map = new HashMap<>(); Collection<Integer> values = map.values(); Iterator it = values.iterator(); while(it.hasNext()){ System.out.println(it.next()); } //遍历key-value Map<String,Integer> map = new HashMap<>(); Set<Map.Entry<String,Integer>> entrys = map.entrySet(); for(Map.Entry<String,Integer> entry:entrys){ String key = entry.getKey(); Integer value = entry.getValue(); System.out.println(key+"---"+value); }提供一个方法,用于遍历HashMap<String,String>中的所有value,并放在list集合中,用上泛型
public List<String> getList(HashMap<String,String> map){ Collection<String> values = map.values(); List<String> list = new ArrayList<>(); for(Stirng value:values){ list.add(value); } return list; }
IO流
File类
- java.io.File:一个对象,文件和文件目录路径的抽象表达形式
- 只涉及到关于文件的操作,并没有涉及到内容的操作。如果需要读写内容,就需要IO流来完成
创建File类的实例
并不会创建出真正的文件,只是将对象加载进内存中
- IDEA中,Junit单元测试方法中,相对路径指的是当前模块下;main()测试中,指的是总工程下
| File(String filePath)绝对路径/相对路径 | File file1 = new File(“hello.txt”),File file2 = new File(“d:\hello.txt”) |
|---|---|
| File(String parentPath,String childPath)父,子目录 | File file3 = new File(“D:\ “,”workspace”) |
| File(File paretPath,String childPath) | File file4 = new File(file3,”hello.txt”); |
常用方法
| String getAbsolutePath() | 获取绝对路径 |
|---|---|
| String getPath() | 获取路径 |
| String getName() | 获取名称 |
| String getParent() | 获取上层文件目录路径,若无,返回null |
| long length() | 获取文件长度(字节),不能获取目录长度 |
| long lastModified() | 获取最后一次修改时间,毫秒值 |
| String[] list() | 获取指定目录下的所有文件或文件目录的名称数组 |
| File[] listFiles() | 获取指定目录下的所有文件或文件目录的File数组 |
| boolean renameTo(File dest) | 把文件重命名为指定的文件路径(要想保证返回true,需要file1在硬盘中存在的,且file2不能在硬盘中存在) |
判断功能
| boolean isDirectory() | 判断是否是文件目录 |
|---|---|
| boolean isFile() | 判断是否是文件 |
| boolean exists() | 判断是否存在 |
创建、删除功能
| boolean createNewFile() | 创建文件,若文件存在则不创建 |
|---|---|
| boolean mkdirs() | 创建文件目录,如果上层文件目录不存在,一并创建 |
| boolean delete() | 删除文件 |
站位:(我们是站在程序(内存)的角度)
输入:将文件写入的内存当中
输出:将内存中的数据存入磁盘
流的分类:
数据单位:字节流(8bit)、字符流(16bit)
流向:输入流、输出流
角色:节点流(File)、处理流(缓冲流是其中的一种)


流
读入数据
从硬盘文件中读取数据到内存中
字符流
//1.实例化File类的对象,指明要操作的对象
File file = new File("hello.txt");
//2.提供具体的流
FileReader fr = new FileReader(file);
//3.数据的读入
//read():返回读入的一个字符,如果达到文件末尾,返回-1
int data = fr.read();//获取的是char转码后的int
while(data != -1){
System.out.println((char)data);
data = fr.read();//获取下一个数据
}
//流的关闭操作
fr.close();
说明:
- read()的理解:返回读入的一个字符,如果到达末尾,返回-1
- 异常处理:为了保证流资源一定可以执行关闭操作,需要使用try-catch-finally(并且判断一下流是否为null)
- 读入的文件一定要存在,否则就会报FileNotFoundException
read(char[ ] cbuf)一次读入多个数据
//1.实例化File类的对象,指明要操作的对象
File file = new File("hello.txt");
//2.提供具体的流
FileReader fr = new FileReader(file);
//3.数据的读入
//read(char[ ] cbuf)一次读入数组长度的数据,如果达到文件末尾,不足长度则返回-1
char[] cbuf = new char[5];//存放数据的地方
int len;//记录数据长度
//方式1
while((len=fr.read(cbuf))!=-1){
for(int i = 0;i<len;i++){
System.out.println(cbuf[i]);
}
}
//方式2
//String str = new String(cbuf,0,len);
//System.out.println(str);
字节流
FileInputStream
操作也是四步骤,1.造文件,2.造流,3.读方法,4.关流
多数据读用byte[]数组
使用字节流处理文本文件可能(在内存中读时)出现乱码:中文
写出数据
从内存中写出数据到硬盘文件里
- 输出操作,对应的File可以不存在
- 如果不存在,回自动创建此文件
- 如果存在:
- 如果使用流构造器为:FileWriter(file/false)/FileWriter(file)对原有的文件覆盖
- 如果流使用构造器为:FileWriter(file/true):不会对原有文件覆盖,而是在原有文件中追加内容
字符流
//1.实例化File类的对象,指明要操作的对象
File file = new File("hello.txt");
//2.提供具体的流
FileWriter fw = new FileWriter(file,false);//默认为false
//3.写出的操作
fw.write("hello");
fw.write("nihao");
//4.流资源的关闭
fw.close();
练习:读写数据
//1.实例化File类的对象,指明要操作的对象
File file1 = new File("hello.txt");
File file2 = new File("hello2.txt");
//2.提供具体的流
FileReader fr = new FileReader(file1);
FileWriter fw = new FileWriter(file2);
//3.数据的读入和写出操作
char[] cbuf = new char[5];
int len ;
//读操作
while((len = fr.read(cbuf))!=-1){
//写入操作
fw.write(cbuf,0,len);//每次读取len个数据
}
//4.流的关闭
fw.close();
fr.close();
字节流
FileOutputStream
操作也是四步骤,1.造文件,2.造流,3.写方法,4.关流
写可以用字节流,因为不涉及到在内存中读
缓冲流
作用:用来提高读写的速度
BufferedInputStreamBufferedOutputStreamBufferedReaderBufferedWriter- 在具体流嵌套一层缓冲流
- 关流:先关外层再关内层,外层关了内层就会自动关闭
读写操作
//1.实例化File类的对象,指明要操作的对象
File file1 = new File("hello.txt");
File file2 = new File("hello2.txt");
//2.提供具体的流
FileReader fr = new FileReader(file1);
FileWriter fw = new FileWriter(file2);
//3.提供缓冲流
BufferedReader br = new BufferedReader(fr);//传入具体的流
BufferedWriter bw = new BufferedWriter(fw);
//数据的读入和写出操作
while((len = br.read(cbuf))!=-1){
//写入操作
bw.write(cbuf,0,len);//每次读取len个数据
}
//关流:先关外层再关内层,外层关了内层就会自动关闭
br.close();
bw.close();
readLine()读写一行的操作
将一行数据读取到字符串中,如果没有值则为null
//1.实例化File类的对象,指明要操作的对象
File file1 = new File("hello.txt");
File file2 = new File("hello2.txt");
//2.提供具体的流
FileReader fr = new FileReader(file1);
FileWriter fw = new FileWriter(file2);
//3.提供缓冲流
BufferedReader br = new BufferedReader(fr);//传入具体的流
BufferedWriter bw = new BufferedWriter(fw);
//4.读写操作
String data ;
while((data=br.readLine())!=null){
bw.write(data+"\n");//方式1换行
//方式2换行
//bw.write(data);
//bw.newLine();
}
练习题
实现文件的复制,使用缓冲流
实现文件的加密操作:
for(i = 0;i<len ;i++){cubf[i] =(byte) (cubf[i]^5);}- 解密只需要对加密对象再异或5就可以实现解密
统计一个文件中所有字符出现的次数
public static void main(String[] args) { BufferedReader br = null; BufferedWriter bw = null; try { //创建文件对象 File file = new File("F:\\123.txt"); File file2 = new File("F:\\1234.txt"); //存放字符和出现的次数 Map<Character,Integer> map = new HashMap<>(); //创建具体流 FileReader fr = new FileReader(file); FileWriter fw = new FileWriter(file2); //创建缓冲流 br = new BufferedReader(fr); bw = new BufferedWriter(fw); //读操作 int len; while((len= br.read())!=-1){ //将len还原成char char ch = (char)len; if(!map.containsKey(ch)){ //字符第一次出现 map.put(ch,1); }else{ //字符出现过,增加1次 map.put(ch,map.get(ch)+1); } } //遍历map集合 Set<Map.Entry<Character,Integer>> set = map.entrySet(); for (Map.Entry<Character,Integer> entry:set) { switch (entry.getKey()){ case ' ': bw.write("空格="+entry.getValue()); break; case '\t': bw.write("tab键="+entry.getValue()); break; case '\n': bw.write("换行="+entry.getValue()); break; case '\r': bw.write("回车="+entry.getValue()); break; default: bw.write(entry.getKey()+"="+entry.getValue()); break; } bw.newLine();//换行 } } catch (IOException e) { e.printStackTrace(); } finally { try { br.close(); } catch (IOException e) { e.printStackTrace(); } try { bw.close(); } catch (IOException e) { e.printStackTrace(); } } }
转换流
- 属于字符流
InputStreamReader:将一个字节输入流转换为字符输入流,父类Reader(看后缀)OutputStreanWriter:将一个字符的输出流转换为字节输出流,父类Writer
- 作用:字节与字符之间的转换
- 解码:字节—>字符:InputStreamReader
- 编码:字符—>字节:OutputStramWriter
InputStreamReader
注意:具体用哪个字符集去读,取决于原来的文件编码是什么
FileInputStream fis = new FileInputStream("123.txt");//字节流
//InputStreamReader isr = new InputStreamReader(fis);//使用系统默认字符集
InputStreamReader isr = new InputStreamReader(fis,"UTF-8");//使用UTF-8去读
//读操作
char[] cbuf = new char[20];
int len;
while((len=isr.read(cbuf))!=-1){
String str = new String(cbuf,0,len);
System.out.println(str);
// for(int i=0;i<len;i++){
// System.out.println(cbuf[i]);
// }
}
isr.close();
转换流实现文件读写
- utf-8—->gbk
FileInputStream fis = new FileInputStream("123.txt");//字节输入流
FileOutpuStream fos = new FileOutStream("1234.txt");//字节输出流
InputStreamReader isr = new InputStreamReader(fis,"UTF-8");//使用UTF-8去读
OutputStreamWriter osw = new OutputStreamWriter(fos,"gbk");//使用gbk去写
字符编码集
ASCII:美国标准,1个字节7位
ISO8859-1:拉丁语表,1个字节8位
GB2312、GBK:中国标准,最多2个字节
Unicode:全世界语言编码集,2个字节,但因为要表示用1个还是2个不能很好界定,没有落地
UTF-8:变长编码方式,1-6个字节,可以根据开头的1 *0来界定用几个字节进行识别
标准流
注意:属于字节流
System.inSystem.out
练习:使用System.in来输入字符串,将其变为大写
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
while(true){
System.out.println("请输入要转换的字符串:");
String data = br.readLine();
if("e".equalsIgnoreCase(data)||"exit".equalsIgnoreCase(data)){
System.out.println("程序结束");
break;
}
System.out.println(data.toUpperCase());
}
br.close();
}
注意:
- IDEA使用单元测试不能在控制台进行输入,需要使用main主程序
- 这里应该使用try-catch-finally,偷懒只实现了主要代码
打印流
PrintStream
PrintWriter
作用:将输出的信息输出在磁盘中
public static void main(String[] args) throws FileNotFoundException {
//创建输出流,指定保存的位置
FileOutputStream fos = new FileOutputStream("F:\\out.txt");
//创建打印流,flush为true,表示换行就会自动刷新
PrintStream ps = new PrintStream(fos,true);
if(ps!=null){
//把标准输出流改为打印流的方式输出(即将控制台输出改为文件输出)
System.setOut(ps);
}
//输出逻辑
for(int i = 0;i<255;i++){
char data = (char)i;
System.out.print(data);
if(i%50==0){
//每50个字符换行
System.out.println();
}
}
//关闭流
ps.close();
}
数据流
DataInputStream读数据
DataOutputStream写数据
- 作用:用于读取或写出基本数据类型的变量或字符串
练习:将内存中的字符串、基本数据类型写出到文件中和读取
//写数据
//创建具体输出流,数据流
DataOutputStream dos = new DataOutputStream(new FileOutputStream("F:\\data.txt"));
//写数据
dos.writeUTF("小明");
dos.flush();
dos.writeInt(12);
dos.flush();
//关流
dos.close();
注意:读数据的时候,读的顺序一定要和写入时一样
//读数据
DataInputStream dis = new DataInputStream(new FileInputStream("F:\\data.txt"));
dis.readUTF();
dis.readInt();
dis.close();
对象流
- 作用:用于存储和读取基本数据类型或对象的处理流
ObjectInputStream:读到内存,反序列化
ObjectOutputStream:写到磁盘或进行网络传输,序列化
- 自定义类(User)序列化的方法:
- 需要自定义类实现接口:
Serializable - 当前类提供一个全局常量:
public static final long serialVersionUID = xxxxxxL;- 算是一个唯一标识,如果没有,再序列化之后,自定义类发生了修改,那么系统将无法识别
- 除了当前自定义类需要实现
Serializable接口,其内部所有属性也必须可序列化(默认情况下,基本数据类型是可序列化的) - 补充:
static/transient修饰的成员变量不能序列化
- 需要自定义类实现接口:
对象序列化机制:允许把Java对象转换为平台无关的二进制流,从而允许把这种二进制流持久化保存在磁盘上,或通过网络这种二进制流传输到另一个网络节点。当其他程序获取到这种二进制流,就可以恢复成原来的java对象。
//序列化,写到磁盘
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("F:\\obj.txt"));
oos.writeObject(new String("hahaha"));
oos.flush();
oos.close();
//反序列化,读到内存
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("F:\\obj.txt"));
String o = (String) ois.readObject();
System.out.println(o);
ois.close();
随机存储文件流
RandomAccessFile
直接继承于java.lang.Object,实现了DataInput和DataOutput接口
既可以作为一个输入流,又可以作为一个输出流
如果作为输出流,写出到的文件不存在时,会自动创建
如果写出到的文件存在,则会对原有文件内容进行覆盖(默认情况下是从头开始覆盖)
RandomAccessFile(File,mode),
- mode:
- r:以只读方式打开
- rw:以读、写
- rwd:读,写,同步
- rws:读写,同步内容+元数据
- mode:
RandomAccessFile raf =new RandomAccessFile(new File("F:\\random.txt"),"r");
RandomAccessFile raf2 = new RandomAccessFile(new File("F:\\random1.txt"),"rw");
byte[] data = new byte[20];
int len;
while((len = raf.read(data))!=-1){
raf2.write(data,0,len);
}
raf.close();
raf2.close();
RandomAccessFile raf2 = new RandomAccessFile(new File("F:\\random1.txt"),"rw");
raf2.write("hahaha".getBytes());//如果写出到的文件存在,则会对原有文件内容进行覆盖
raf2.close();
面试题
字节流与字符流的区别与使用情景
字节流: read(byte[] buffer)/read() 非文本文件,如果只是复制文件,不在控制台输出,字节流也可以实现 字符流: read(char[] cbuf)/read() 文本文件使用缓冲流实现a.jpg复制到b.jpg
//创建具体流 FileInputStream fis = new FileInputStream("F:\\123.txt"); FileOutputStream fos = new FileOutputStream("F:\\1234.txt"); //创建缓冲流 BufferInputStream bis = new BufferInputStream(fis); BufferOutputStream bos = new BufferOutputStream(fos); //读写操作 int len; byte[] data = new Byte[1024]; while((len = bis.read(data))!=-1){ //写操作 bos.write(byte,0,len); } bis.close(); bos.close();转换流是哪两个类,分别的作用是什么?
InputStreamReader:将输入的字节流转换为输入的字符流,解码 OutputStreamWriter:将输出的字符流转换为输出的字节流,编码 InputStreamReader isr = new InputStreamReader(new FileInputStream("1.txt"),"utf-8");//根据文件的编码来读 OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("1.txt"),"gbk");//需要转换什么编码就写什么总结遍历方式
字节流: read(byte[] buffer)/read() //方式1:数组写 int len; byte[] data = new byte[1024]; while((len = bis.read(data))!=-1){ bos.write(byte,0,len); } //方式2:逐个字节写 int len; byte[] data = new byte[1024]; while((len = bis.read(data))!=-1){ for(int i=0;i<len;i++){ bos.write(data[i]); } } //方式3:字符串读行 String data; while((data = bis.readLine())!=null){ bos.write(data); //bos.newLine();//换行 } //方式4:数组转字符串 byte[] cbuf = new byte[1024]; int len; while((len = bis.read(cbuf))!=-1){ String data = new String(cbuf,0,len); bos.write(data); } 字符流: read(char[] cbuf)/read()
网络编程
网络通信三要素
IP:电子设备(计算机)在网络中的唯一标识。对应的类:InetAddress
- IPv4
- IPv6
端口:应用程序在计算机中的唯一标识。 0~65536
- 公认端口:0~1023
- 注册端口:1023~49151
- 端口号与IP地址组合得到一个网络套接字:Socket
传输协议:规定了数据传输的规则
- 基础协议:
- tcp:安全协议,三次握手,进行大数据量传输。 速度稍慢
- udp:不安全协议。 速度快,以数据包的形式发送。只负责发,不管对方是否接收到
- 基础协议:
网络通信落地分为4层:应用层、传输层、网络层、物理+数据链路层
InetAddress实例化
IP对象实例化(没有构造方法,可以静态创造)
getByName(String host),getLocalhost()
InetAddress inet1 = InetAddress.getByName("192.168.10.14");
InetAddress inet2 = InetAddress.getByName("www.baidu.com");
InetAddress inet3 = InetAddress.getLocalhost();
方法
getHostName():获取域名getHostAddress():获取主机地址
实现客户端-服务器交互
注意:
- 客户端创建的Socket是服务器端的套接字(ip+port)
- 服务器端需要先获取客户端的socket,才能获取流
实现消息交互
//客户端
public void client(){
Socket socket = null;
OutputStream os = null;
try {
//1.创建套接字,指明服务器IP和端口
InetAddress inetAddress = InetAddress.getLocalHost();
socket = new Socket(inetAddress,6666);
//2.获取输出流
os = socket.getOutputStream();
//3.发送数据
os.write("你好".getBytes());
} catch (IOException e) {
e.printStackTrace();
}finally {
//4.关闭流和套接字
if(os!=null){
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(socket!=null){
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
//服务器端
//这里偷懒将异常抛出,应该使用try-catch
public void server() throws IOException {
//1.创建ServerSocket,指明端口
ServerSocket ss = new ServerSocket(6666);
//2.获取客户端的socket,表示接收来自客户端的消息
Socket socket = ss.accept();
//3.获取输入流
InputStream is = socket.getInputStream();
//4.读取操作
byte[] data = new byte[1024];
int len;
while((len = is.read(data))!=-1){
String str = new String(data,0,len);
System.out.print(str);
//socket.getInetAddress()获取ip对象
System.out.println("收到来自"+socket.getInetAddress().getHostAddress()+"的消息");
}
//5.关闭流、socket、服务器
is.close();
socket.close();
ss.close();
}
服务器端保存客户端发送的图片
服务器端接收完成后反馈消息,客户端接收消息
- 需要的流
- 客户端
- socket
- 文件输入流(读图片)
- 输出流(发送用)通过socket获取
- 输入流(读服务器端反馈的消息)通过socket获得
- 服务端
- 客户端的socket
- 输入流(读客户端的图片)通过socket获取
- 文件输出流(保存用)
- 输出流(发送反馈消息)通过Socket获取
- 客户端
注意:
异常需要用try-catch,这里偷懒
客户端的输出流和服务器端的输入流都是从Socket获取的
只有从本地读取 和保存是自己创建的
中断传输:socket.shutdownOutput();
//客户端
public void client1() throws IOException {
//1.获取Ip对象
InetAddress inetAddress = InetAddress.getByName("127.0.0.1");
//2.获取socket
Socket socket = new Socket(inetAddress,6667);
//4.获取输出流(用于发送图片)
OutputStream os = socket.getOutputStream();
//3.获取输入流(用于读取本地图片)
FileInputStream fis = new FileInputStream("F:\\123.txt");
//5.读写操作
byte[] data = new byte[1024];
int len ;
while ((len = fis.read(data))!=-1){
os.write(data,0,len);
}
//中断传输,表示自己已经传输完成,不再继续传输
socket.shutdownOutput();
//6.获取服务器端反馈的消息
//6.1.获取输入流(读服务器端反馈的消息)
InputStream is = socket.getInputStream();
byte[] data2 = new byte[1024];
int len2;
while((len = is.read(data2))!=-1){
String str = new String(data2,0,len);
System.out.println(str);
}
//7.关闭流、socket
is.close();
os.close();
fis.close();
socket.close();
}
//服务器端
@Test
public void server() throws IOException {
//1.获取ServerSocket对象
ServerSocket ss = new ServerSocket(6667);
//2.获取客户端的socket
Socket socket = ss.accept();
//3.获取输入流(用于从客户端获取图片)
InputStream is = socket.getInputStream();
//4.获取输出流(保存本地)
FileOutputStream fos = new FileOutputStream("F:\\321.txt");
//5.读写操作
byte[] data = new byte[1024];
int len;
while((len = is.read(data))!=-1){
fos.write(data,0,len);
}
//6.服务器端发送反馈信息
//6.1获取输出流
OutputStream os = new socket.getOutputStream();
os.write("收到文件,谢谢!".getBytes());
//7.关闭流、socket、服务器
os.close();
fos.close();
is.close();
ss.close();
}
URL的实例化及常用方法
统一资源定位符
URL url = new URL("http://localhost:8080/examples/123.txt?username=tom")
| getProtocol() | 获取协议名 |
|---|---|
| getHost() | 获取主机名 |
| getPort() | 获取端口号 |
| getPath() | 获取文件路径 |
| getFile() | 获取文件名 |
| getQuery() | 获取查询名 |
使用tomcat复制文件
中断连接:urlConnection.disconnect();
public static void main(String[] args) throws IOException {
//创建url对象
URL url = new URL("http://localhost:8080/examples/123.txt");
//获取 获取连接的对象
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
//获取连接
urlConnection.connect();
//获取输入流(用于读连接中的数据)
InputStream is = urlConnection.getInputStream();
//获取输出流(用于存入硬盘)
FileOutputStream fos = new FileOutputStream("F:\\1234.txt");
byte[] data = new byte[1024];
int len;
while((len = is.read(data))!=-1){
fos.write(data,0,len);
}
//关闭流,中断连接
fos.close();
is.close();
urlConnection.disconnect();
}



