Redis
概念: redis是一款高性能的NOSQL系列的非关系型数据库
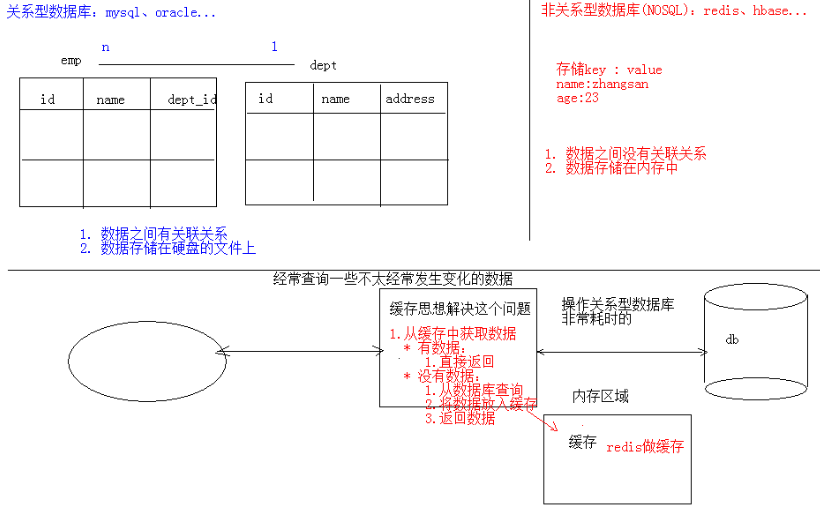
1.1.什么是NOSQL
NoSQL(NoSQL = Not Only SQL),意即“不仅仅是SQL”,是一项全新的数据库理念,泛指非关系型的数据库。
1.1.1. NOSQL和关系型数据库比较
优点:
1)成本:nosql数据库简单易部署,基本都是开源软件,不需要像使用oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
2)查询速度:nosql数据库将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,自然查询速度远不及nosql数据库。
3)存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
4)扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。
缺点:
1)维护的工具和资料有限,因为nosql是属于新的技术,不能和关系型数据库10几年的技术同日而语。
2)不提供对sql的支持,如果不支持sql这样的工业标准,将产生一定用户的学习和使用成本。
3)不提供关系型数据库对事务的处理。
1.1.2. 非关系型数据库的优势:
1)性能NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。
2)可扩展性同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
1.1.3. 关系型数据库的优势:
1)复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
2)事务支持使得对于安全性能很高的数据访问要求得以实现。对于这两类数据库,对方的优势就是自己的弱势,反之亦然。
1.1.4. 总结
关系型数据库与NoSQL数据库并非对立而是互补的关系,即通常情况下使用关系型数据库,在适合使用NoSQL的时候使用NoSQL数据库,
让NoSQL数据库对关系型数据库的不足进行弥补。
一般会将数据存储在关系型数据库中,在nosql数据库中备份存储关系型数据库的数据
1.2.主流的NOSQL产品
• 键值(Key-Value)存储数据库
相关产品: Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
典型应用: 内容缓存,主要用于处理大量数据的高访问负载。
数据模型: 一系列键值对
优势: 快速查询
劣势: 存储的数据缺少结构化
• 列存储数据库
相关产品:Cassandra, HBase, Riak
典型应用:分布式的文件系统
数据模型:以列簇式存储,将同一列数据存在一起
优势:查找速度快,可扩展性强,更容易进行分布式扩展
劣势:功能相对局限
• 文档型数据库
相关产品:CouchDB、MongoDB
典型应用:Web应用(与Key-Value类似,Value是结构化的)
数据模型: 一系列键值对
优势:数据结构要求不严格
劣势: 查询性能不高,而且缺乏统一的查询语法
• 图形(Graph)数据库
相关数据库:Neo4J、InfoGrid、Infinite Graph
典型应用:社交网络
数据模型:图结构
优势:利用图结构相关算法。
劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案。
1.3 什么是Redis
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,且Redis通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止Redis支持的键值数据类型如下:
1) 字符串类型 string
2) 哈希类型 hash
3) 列表类型 list
4) 集合类型 set
5) 有序集合类型 sortedset
1.3.1 redis的应用场景
• 缓存(数据查询、短连接、新闻内容、商品内容等等)
• 聊天室的在线好友列表
• 任务队列。(秒杀、抢购、12306等等)
• 应用排行榜
• 网站访问统计
• 数据过期处理(可以精确到毫秒
• 分布式集群架构中的session分离
表锁:MyISAM
行锁:Innodb
大数据:3v:海量数据、数据多样、实时数据 3高:高并发、高可拓、高性能
单线程:redis是基于内存操作,CPU不是Redis性能瓶颈,而是根据内存和网络带宽,redis将全部数据放在内存当中。
下载安装
- 官网:https://redis.io
- 中文网:http://www.redis.net.cn/
- 解压直接可以使用:
- redis.windows.conf:配置文件
- redis-cli.exe:redis的客户端
- redis-server.exe:redis服务器端
命令操作
redis的数据结构:
- redis存储的是:key,value格式的数据,其中key都是字符串,value有5种不同的数据结构
- value的数据结构:
- 字符串类型 string
- 哈希类型 hash : map格式
- 列表类型 list : linkedlist格式。支持重复元素
- 集合类型 set : 不允许重复元素
- 有序集合类型 sortedset:不允许重复元素,且元素有顺序
- value的数据结构:
1. 字符串类型 string
存储: set key value
127.0.0.1:6379> set username zhangsan OK获取: get key
127.0.0.1:6379> get username "zhangsan"删除: del key
127.0.0.1:6379> del age (integer) 1增加字符串:APPEND
如果key不存在,就相当于set
获取字符串长度:STRLEN
自增1:incr
自减1:decr
自增步长:INCRBY
<步长> 自减步长:DECRBY
<步长> 截取字符串:GETRANGE
<起始索引0> <终止索引> 如:03就是[0,3],0 -1就是get 替换字符串:SETRANGE
<索引> 如:原来是abcc ,1 aa 就是aaac 设置过期时间:setex
<秒> 不存在时再set:setnx
批量set/get/setex/setnx:mset
先get后set:getset
如果存在值就获取原值,并设置新值
2. 哈希类型 hash
存储: hset key field value
127.0.0.1:6379> hset myhash username lisi (integer) 1 127.0.0.1:6379> hset myhash password 123 (integer) 1批量存储:hmset
获取:
hget key field: 获取指定的field对应的值
127.0.0.1:6379> hget myhash username "lisi"批量获取:hmget
获取所有field:hkeys
获取所有value:hvals
hgetall key:获取所有的field和value
127.0.0.1:6379> hgetall myhash 1) "username" 2) "lisi" 3) "password" 4) "123"
删除: hdel key field
127.0.0.1:6379> hdel myhash username (integer) 1key中键值对数量:hlen
判断key中是否存在key:hexists
按步长增加value的值:hincrby/hincrbyfloat
<步长> 不存在时再set:hsetnx
3. 列表类型 list:可以添加一个元素到列表的头部(左边)或者尾部(右边)
添加:
lpush key value: 将元素加入列表左表
rpush key value:将元素加入列表右边
127.0.0.1:6379> lpush myList a (integer) 1 127.0.0.1:6379> lpush myList b (integer) 2 127.0.0.1:6379> rpush myList c (integer) 3
获取:
- lrange key start end :范围获取
127.0.0.1:6379> lrange myList 0 -1 1) "b" 2) "a" 3) "c" - lindex
:通过下标获取值,从0开始
- lrange key start end :范围获取
删除:
- lpop key: 删除列表最左边的元素,并将元素返回
- rpop key: 删除列表最右边的元素,并将元素返回
- lrem
<数量> :移除对应数量的值
获取列表长度:Llen
截取:ltrim
<起始index><终止index> 移除列表最后一个元素,并移动到新列表中:rpoplpush
更新值,将列表指定下标的值替换为另一个值:lset
,不存在会报错
4. 无序集合类型 set : 不允许重复元素
存储:sadd key value
127.0.0.1:6379> sadd myset a (integer) 1 127.0.0.1:6379> sadd myset a (integer) 0获取:smembers key:获取set集合中所有元素
127.0.0.1:6379> smembers myset 1) "a"判断是否有该值:sismember
删除:srem key value:删除set集合中的某个元素
127.0.0.1:6379> srem myset a (integer) 1获取集合里面的元素个数:scard
随机出几个数字:srandmember
随机出栈:spop
将key1的值转到key2里:smove
差集(在set1中,不在set2中的值):sdiff
交集:sinter
并集:sunion
5. 有序集合类型 sortedset:不允许重复元素,且元素有顺序.每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
存储(可批量):zadd key score value
127.0.0.1:6379> zadd mysort 60 zhangsan (integer) 1 127.0.0.1:6379> zadd mysort 50 lisi (integer) 1 127.0.0.1:6379> zadd mysort 80 wangwu (integer) 1获取:zrange/zrevrange key start end [withscores]
127.0.0.1:6379> zrange mysort 0 -1 1) "lisi" 2) "zhangsan" 3) "wangwu" 127.0.0.1:6379> zrange mysort 0 -1 withscores 1) "zhangsan" 2) "60" 3) "wangwu" 4) "80" 5) "lisi" 6) "500"根据分数获取:zrangebyscore/zrevrangebyscore
<开始score><结束score> [“( ”表示不包含]:zrangebyscore
<开始score>(<结束score>: 开始≤分数<结束 截取:zrangebyscore
<开始score><结束score> limit <截取个数> 删除:zrem key value
127.0.0.1:6379> zrem mysort lisi (integer) 1集合里面的元素个数:zcard
集合区间内的元素个数:zcount
<开始score><结束score> 元素的下标:zrank/zrevrank
元素的分数:zscore
6. 通用命令
- keys * : 查询所有的键
- type key : 获取键对应的value的类型
- del key:删除指定的key value
- select
:切换数据库 - DBSIZE:数据库key的数量
- flushdb:清空数据库
- flushAll:清空全部数据库
- EXIST
:是否存在 - EXPIRE
<秒>:设定过期时间 - ttl
:查看剩余时间
持久化
redis是一个内存数据库,当redis服务器重启,获取电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘的文件中。
redis持久化机制:
RDB:默认方式,不需要进行配置,默认就使用这种机制
原理:
在指定时间间隔内将内存中的数据集快照写入到磁盘中,当需要恢复的时候再将磁盘中的快照读到内存里
redis会单独创建(fork)一个子线程进行持久化操作,会先将数据集写入到临时文件中,当持久化过程结束之后,临时文件就会替换原持久化好的rdb文件。在整个过程中,主进程没有任何io操作,确保了极高的性能。
优点:
- 适合于大规模数据的恢复
- 对数据的完整性要求不高
缺点:
- 容易丢失最后一次修改的数据,需要一定的时间间隔进程操作
- 在fork进程的时候,会占用一定的内存空间
编辑redis.windwos.conf文件
after 900 sec (15 min) if at least 1 key changed save 900 1 after 300 sec (5 min) if at least 10 keys changed save 300 10 after 60 sec if at least 10000 keys changed save 60 10000重新启动redis服务器,并指定配置文件名称
在此处打开命令行 redis-server.exe redis.windows.conf
AOF:日志记录的方式,可以记录每一条命令的操作。可以每一次命令操作后,持久化数据
原理:
以日志的形式记录每一次写操作,将redis执行过的每一个写的指令记录下来,只能追加文件,不能改写文件,在刚启动redis的时候会读取文件重新构建数据。
优点:
- 每一次修改都会保存,文件的完整性好
- 每秒同步一次,只可能丢失一秒的数据
- 从不同步,效率最高
缺点:
- 数据文件aof要比rdb大很多,修复的速度要比rdb慢
- aof运行时要进行读写的操作,运行效率f会比rdb慢
编辑redis.windwos.conf文件
appendonly no(关闭aof) --> appendonly yes (开启aof) # appendfsync always : 每一次操作都进行持久化 appendfsync everysec : 每隔一秒进行一次持久化 # appendfsync no : 不进行持久化重新启动redis服务器,并指定配置文件名称
在此处打开命令行 redis-server.exe redis.windows.conf
Java客户端 Jedis
Jedis: 一款java操作redis数据库的工具.
使用步骤:
- 下载jedis的jar包
- 使用
- 获取连接
Jedis jedis = new Jedis(“localhost”,6379);
- 获取连接
- 操作
jedis.set("username","zhangsan");- 关闭连接
jedis.close();
Jedis操作各种redis中的数据结构
字符串类型 string
setget
哈希类型 hash : map格式
hset hgethgetAll
列表类型 list : linkedlist格式。支持重复元素
lpush / rpush lpop / rpoplrange start end : 范围获取
集合类型 set : 不允许重复元素
saddsmembers:获取所有元素
有序集合类型 sortedset:不允许重复元素,且元素有顺序
zaddzrange
jedis连接池: JedisPool
- 使用:
- 创建JedisPool连接池对象 new JedisPool([config],[“localhost”],[6379])
- 调用方法 getResource()方法获取Jedis连接
- 使用
//0.创建一个配置对象 JedisPoolConfig config = new JedisPoolConfig(); config.setMaxTotal(50); config.setMaxIdle(10); //1.创建Jedis连接池对象 JedisPool jedisPool = new JedisPool(config,"localhost",6379); //2.获取连接 Jedis jedis = jedisPool.getResource(); //3. 使用 jedis.set("hehe","heihei"); //4. 关闭 归还到连接池中 jedis.close();- 连接池工具类(加载配置文件,获取Jedis方法)
public class JedisPoolUtils { private static JedisPool jedisPool; static{ //读取配置文件 InputStream is = JedisPoolUtils.class.getClassLoader().getResourceAsStream("jedis.properties"); //创建Properties对象 Properties pro = new Properties(); //关联文件 try { pro.load(is); } catch (IOException e) { e.printStackTrace(); } //获取数据,设置到JedisPoolConfig中 JedisPoolConfig config = new JedisPoolConfig(); config.setMaxTotal(Integer.parseInt(pro.getProperty("maxTotal"))); config.setMaxIdle(Integer.parseInt(pro.getProperty("maxIdle"))); //初始化JedisPool jedisPool = new JedisPool(config,pro.getProperty("host"),Integer.parseInt(pro.getProperty("port"))); } /** * 获取连接方法 */ public static Jedis getJedis(){ return jedisPool.getResource(); } }
- 使用:
案例
bug1:查询后的列表:undefind
没有遍历获取的集合
$.get("findProvinceServlet",{},function (data) {
//遍历
$(data).each(function () {
var option = "<option id='"+this.id+"'>"+this.name+"</option>";
$("#province").append(option);
})
})
bug2:JedisConnectionException: Could not get a resource from the pool
没有开redis服务器
在运行前要先开启redis服务器挂着
案例需求:
1. 提供index.html页面,页面中有一个省份 下拉列表
2. 当 页面加载完成后 发送ajax请求,加载所有省份
* 注意:使用redis缓存一些不经常发生变化的数据。
* 数据库的数据一旦发生改变,则需要更新缓存。
* 数据库的表执行 增删改的相关操作,需要将redis缓存数据情况,再次存入
* 在service对应的增删改方法中,将redis数据删除。
//1.查询redis缓存中是否有数据
//1.1创建jedis
Jedis jedis = RedisUtils.getJedis();
String province_json = jedis.get("province");
if(province_json==null||province_json.length()==0){
//没有数据,查询数据库
List<Province> list = provinceDao.findProvince();
//将数据序列化为json对象
ObjectMapper mapper = new ObjectMapper();
try {
province_json = mapper.writeValueAsString(list);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
//存储进缓存中
jedis.set("province",province_json);
jedis.close();
}else {
return province_json;
}
配置文件
网络
bind 127.0.0.1 #绑定的Ip
protected-mode yes # 保护模式
port 6379 #端口设置
通用GENERAL
daemonize yes # 以守护进程的方式运行,默认为no,需要手动开启为yes
pidfile /var/run/redis_6379.pid # 如果以后台的方式运行,我们就需要指定一个pid文件
#日志
# notive生产环境
loglevel notice
logfile "" #日志的文件位置名
databases 16 # 数据库的数量,默认为16个
always-show-logo yes #是否显示logo
事务
Redis单条命令是保持原子性的,但是事务不保证原子性,没有隔离级别的概念
一次性、顺序性、排他性
所有命令在事务中,并没有直接被执行,只有执行命令之后才会被执行
开启事务:multi
命令入队:。。。
执行事务:exec
放弃事务:discard
编译型异常(代码有问题):所有命令都不会执行
运行时异常:其他命令依然正常执行
消息订阅发布
先订阅后发布
订阅端、频道、发布端
订阅:subscribe <频道名称>
发布:publish <频道名称> <消息>
退订:unsubscribe <频道名称>
原理:redis-server里维护了一个字典,字典的键就是一个个频道,值是一个链表,链表中保存了所有订阅的客户端,订阅的命令核心就是将客户端添加到订阅的链表中。发布就是根据频道在字典中查到对应的值,遍历这个链表将其发布给订阅者。
主从复制
指将一台redis服务器的数据,复制到其他redis服务器。
数据的复制时单向的,只有主节点到从节点
单个redis最大使用内存不应该超过20G
作用:
- 数据冗余
- 故障恢复
- 负载均衡:读写分离,主机为写为主,从机以读为主(只要配置了主从关系,就自动实现了这一点)
- 高可用(集群)基石:哨兵模式、集群能够实施的基础
环境配置
只配置从库,不用配置主库
复制3个配置文件,然后修改对应的信息
- port端口(主不变,从变)
- pidfile名字 (不改为空)
- log文件名字
- dump.rdb名字
修改之后,启动3个redis服务器,可以通过进程信息查看 ps -ef|grop redis
查看当前库的信息:info replication(能看到角色master,从机数量)
认老大:slaveof 127.0.0.1 6379
想要持久化主从关系,需要在配置文件中配置 replicaof <主ip> <主port>
测试:主机断开连接,从机依然可以连接到主机,但仍不能进行写操作,主机连接上之后,从机依然能读到主机写的新数据
测试:如果使用命令行配置主从,从机断开连接,会变回主机
复制原理:
从机成功连接主机之后,会发送一条sync同步命令,主机接到命令,会启动后台存盘进程,同时收集所有用于修改数据集的命令,在后台进程执行完毕之后,主机会传送整个数据文件到从机,实现完全同步
全量复制:从机接收到数据库文件,将其加载进内存
增量复制:连接后,主机新收集的修改命令给从机,完成同步
连接方式
- 一主二仆
- 层层链路:M-S(M)-S,即当主又当从的节点,仍然不能写
- 谋朝篡位:如果主机断开连接,使用
slaveof no one,让自己变为主机,其他节点归顺
哨兵模式
原理:哨兵通过发送命令,等待redis服务器回应,从而监控运行的多个redis实例
当主服务器宕机,哨兵1检测到结果,系统并不会进行failover(故障转移)操作,当之后的哨兵也检测到不可用,数量达到一定值,哨兵间就会进行投票,进行故障转移(选新主机)操作。切换成功后发布订阅模式,让各个监控的从服务器切换主机
步骤:
目前状态时1主2从
配置哨兵配置文件 sentinel.conf
sentinel monitor 被监控的名称 127.0.0.1 6379 1 # 后面的数字1,代表主机挂了,从机投票看谁接替为主机启动哨兵
redis-sentinel kconfig/sentinel.conf
当主机回来了,只能归到新的主机下,当作从机
优点:
- 哨兵集群,基于主从复制模式,所有的主从配置优点都有
- 主从自动切换,故障可以转移,系统可用性更好
缺点:
- Redis不好在线扩容,集群容量达到上限,扩容就会很麻烦
- 哨兵模式配置麻烦
缓存穿透、雪崩
缓存穿透概念:当查询一个数据,内存数据库中没有,也就是缓存没有命中,就去持久层查询,持久层也没有,本次查询失败,当用户很多的时候,缓存都没有命中(秒杀),都去访问持久层,带来了很大的压力,这就是缓存穿透。(大面积查不到)
缓存穿透概念:缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
- 接口层增加校验,如用户信息校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
布隆过滤器:是一种数据结构,对所有可能查询的参数以哈希的形式存储,在控制层先进行校验,不符合就会被丢弃,减缓存储系统压力。
缓存空对象:当存储层不命中的时候,返回的空对象将其缓存起来,同时设定一个过期时间,之后如果再访问这个数据就可以在换从获取,避免了后端数据源压力。
缓存空对象的两个问题:
- 如果空值被缓存起来,意味着缓存需要更大的空间去存储更多的键
- 即使对空值设置了过期时间,还是会存在缓存层和存储层有一段时间不一致,对于要保持一致性的业务有影响
缓存击穿概念(量太大,缓存过期):指一个Key非常热点,大并发集中在一个点上访问,当这个key失效的瞬间,持续的大并发就会穿破缓存,直接访问数据库。这一瞬间叫做缓存击穿。
解决方案:
设置热点数据永不过期
加互斥锁:分布式锁,保证对于每一个key只有一个线程可以访问后端服务,其他线程没有访问权限,只需要等待即可。这种方式将高并发的压力转移给了分布式锁。
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同缓存数据库中。
- 设置热点数据永远不过期。
- 数据预热:在正式部署之前,先把数据提前访问一遍,保证大量访问的数据加载进缓存中。将大并发的数据设定不同的key和过期时间,失效时间尽量均匀分布。
- 限流降级:通过加锁、队列来控制读数据库写缓存的线程数量



