框架(Framework)
Mybatis
- 是一个优秀的基于 java 的持久层框架,它内部封装了 jdbc,使开发者只需要关注 sql语句本身, 而不需要花费精力去处理加载驱动、创建连接、创建 statement 等繁杂的过程
- 采用 ORM 思想解决了实体和数据库映射的问题
- Mybatis 与 JDBC 编程的比较

Mybatis 框架开发的准备
- 下载相关的 jar 包或 maven 开发的坐标:Mybatis 版本是 3.4.5 版本
搭建 Mybatis 开发环境
创建 maven 工程
添加 Mybatis 3.4.5 的坐标(依赖)
<dependencies> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.4.5</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.10</version> <scope>test</scope> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.6</version> <scope>runtime</scope> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.12</version> </dependency> </dependencies>编写 User 实体类
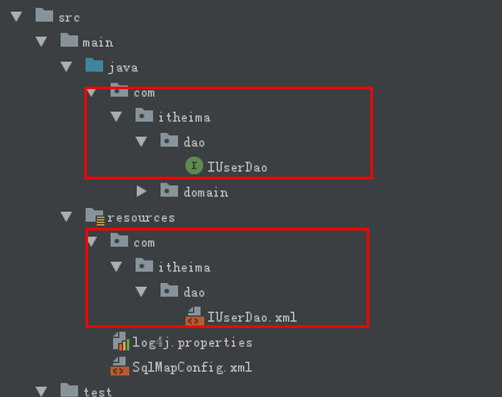
编写持久层接口 IUserDao (也可以写成 UserDao 或者 UserMapper)
编写持久层接口的映射文件 IUserDao.xml (也可使用注解,不编写映射文件,具体方法在8)
- 要求:
- 创建位置:必须和持久层接口在相同的包中。(目录和包不一样,需要创建三次,一次性创建为一级目录)
- 名称:必须以持久层接口名称一样,扩展名是.xml
- 要求:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- 参数namespace是接口全类名 -->
<mapper namespace="com.itheima.dao.IUserDao">
<!-- 配置查询所有操作 --> <!-- 参数id是接口的方法名,resultType是实体类的全类名 -->
<select id="findAll" resultType="com.itheima.domain.User">
select * from user
</select>
</mapper>
- 编写 SqlMapConfig.xml 配置文件
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 配置 mybatis 的环境 --> <!-- 参数随便起 -->
<environments default="mysql">
<!-- 配置 mysql 的环境 --> <!-- 参数与default保持一致-->
<environment id="mysql">
<!-- 配置事务的类型 -->
<transactionManager type="JDBC"></transactionManager>
<!-- 配置连接数据库的信息:用的是数据源(连接池) -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/eesy"/>
<property name="username" value="root"/>
<property name="password" value="1234"/>
</dataSource>
</environment>
</environments>
<!-- 告知 mybatis 映射配置的位置 -->
<mappers>
<mapper resource="com/itheima/dao/IUserDao.xml"/>
</mappers>
</configuration>
快速入门
- 编写测试类:
public static void main(String[] args) throws IOException { //1.读取配置文件 InputStream is = Resources.getResourceAsStream("SqlMapConfig.xml"); //2.创建SqlSessionFactory构建者对象 SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); //3.使用构建者创建工程对象SqlSessionFactory SqlSessionFactory factory = builder.build(is); //4.使用工厂生产SqlSession对象 SqlSession session = factory.openSession(); //5.使用SqlSession对象创建Dao接口代理对象 IUserDao userDao = session.getMapper(IUserDao.class); //此处也可以写session.select(名称空间.方法id);直接进行crud操作,此时名称空间是随意起的,也不需要接口 //6.使用代理对象执行查询所有的方法 List<User> users = userDao.findAll(); for (User user :users) { System.out.println(user); } //7.释放资源 session.close(); is.close(); }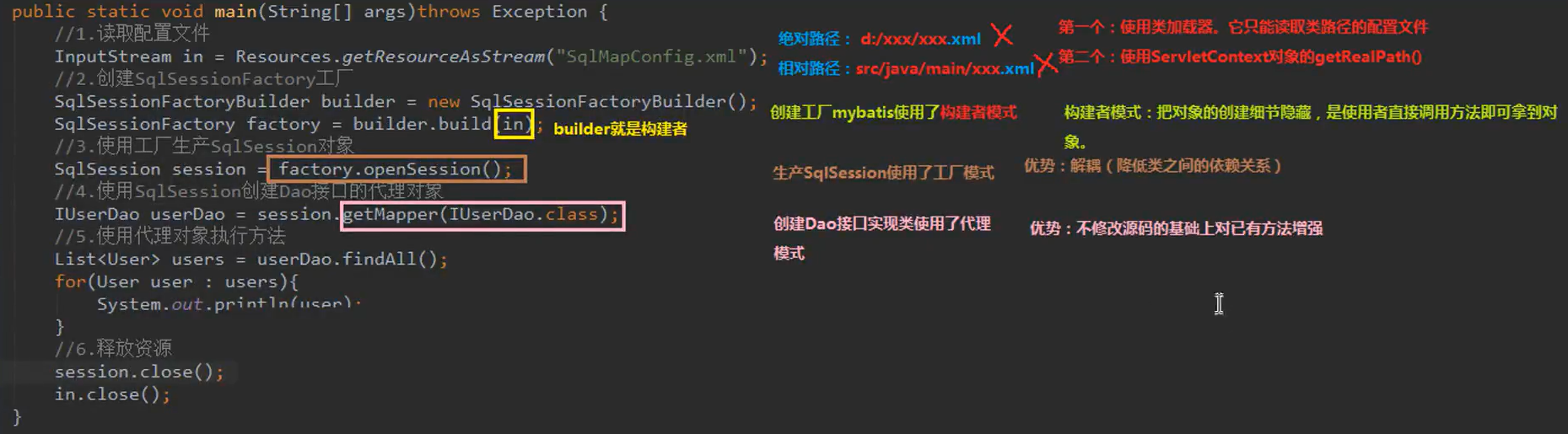
使用注解,不使用映射配置文件
- 将dao接口上加上注解:
@select("select * from user")- 修改mybatis总配置中的映射配置
<mapper class="cn/hm/dao/IUserDao"/>- 注意:在使用基于注解的 Mybatis 配置时,请移除 xml 的映射配置(IUserDao.xml)。
自定义Mybatis底层
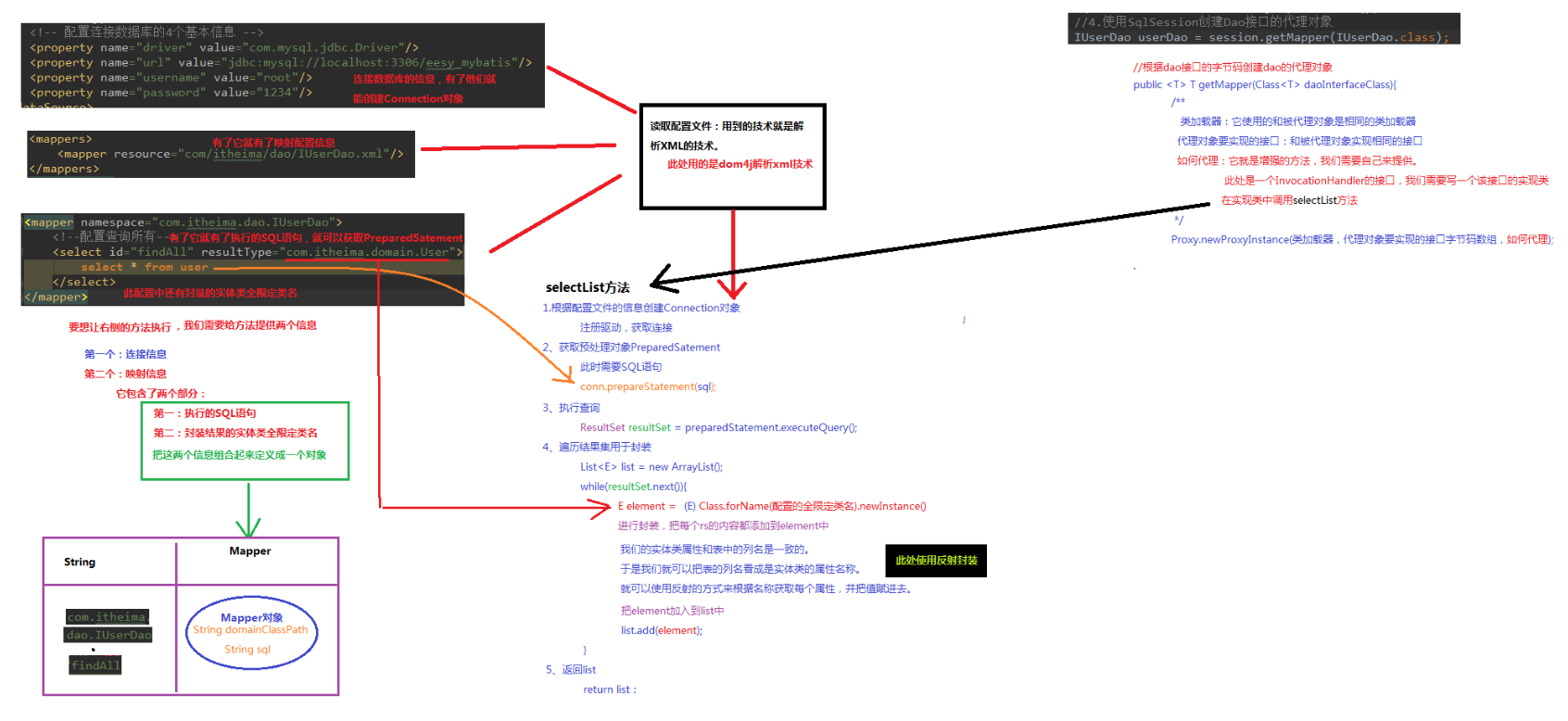
CRUD操作
- 使用要求:
- 持久层接口和持久层接口的映射配置必须在相同的包下
- 持久层映射配置中 mapper 标签的 namespace 属性取值必须是持久层接口的全限定类名
- SQL 语句的配置标签
插入操作:
1.在持久层接口中添加新增方法 void saveUser(User user);
2.在用户的映射配置文件中配置
<!-- 保存用户-->
<insert id="saveUser" parameterType="com.itheima.domain.User">
insert into user(username,birthday,sex,address)
values(#{username},#{birthday},#{sex},#{address})
</insert>
2.1.在总配置文件中加上映射配置 <mapper resource="cn/hm/dao/IUserDao.xml"/>
细节:
parameterType 属性:
代表参数的类型,因为我们要传入的是一个类的对象,所以类型就写类的全名称。
sql 语句中使用#{}字符:
它代表占位符,相当于原来 jdbc 部分所学的?,都是用于执行语句时替换实际的数据。
具体的数据是由#{}里面的内容决定的。
#{}中内容的写法:
由于我们保存方法的参数是 一个 User 对象,此处要写 User 对象中的属性名称。
它用的是 ognl 表达式。
ognl 表达式:
它是 apache 提供的一种表达式语言,
全称是: Object Graphic Navigation Language 对象图导航语言
它是按照一定的语法格式来获取数据的。
语法格式就是使用 #{对象.对象}的方式
#{user.username}它会先去找 user 对象,然后在 user 对象中找到 username 属性,并调用 getUsername()方法把值取出来。但是我们在 parameterType 属性上指定了实体类名称,所以可以省略 user. 而直接写 username
3.添加测试类中的测试方法
@Test
public void testSave(){
User user = new User();
user.setUsername("modify User property");
user.setAddress("北京市顺义区");
user.setSex("男");
user.setBirthday(new Date());
//执行保存方法
userDao.saveUser(user);
}
打开 Mysql 数据库发现并没有添加任何记录,原因是什么?
这一点和 jdbc 是一样的,我们在实现增删改时一定要去控制事务的提交,那么在 mybatis 中如何控制事务 提交呢?
可以使用:
session.commit();
加入事务提交后的代码如下:
@After//在测试方法执行完成之后执行
public void destroy() throws Exception{
session.commit();
//释放资源
session.close();
in.close(); }
拓展:查询新增用户 id 的返回值
在insert标签体内
<!-- 配置保存时获取插入的 id 参数表中列名称、类中属性名、执行时期、返回值类型-->
<selectKey keyColumn="id" keyProperty="id" order="AFTER" resultType="int">
select last_insert_id();
</selectKey>
修改操作:
1.在持久层接口中添加更新方法 int updateUser(User user);
2.在用户的映射配置文件中配置
<!-- 更新用户 -->
<update id="updateUser" parameterType="com.itheima.domain.User">
update user set username=#{username},birthday=#{birthday},sex=#{sex}, address=#{address} where id=#{id}
</update>
3.加入更新的测试方法
@Test
public void testUpdateUser()throws Exception{
//1.根据 id 查询
User user = userDao.findById(52);
//2.更新操作
user.setAddress("北京市顺义区");
int res = userDao.updateUser(user);
System.out.println(res); }
删除操作:
1.在持久层接口中添加删除方法 int deleteUser(Integer userId);
2.在用户的映射配置文件中配置
<!-- 删除用户 注意,该参数是Int类型,可以是int,Integer,java.lang.Integer-->
<delete id="deleteUser" parameterType="java.lang.Integer">
<!-- 注意:#{}只是个占位符,如果只有一个参数且是基本数据类型就可以随便填写-->
delete from user where id = #{uid}
</delete>
3.加入删除的测试方法
@Test
public void testDeleteUser() throws Exception {
//执行操作
int res = userDao.deleteUser(52);
System.out.println(res); }
查询一个操作:
1.在持久层接口中添加 findById 方法
2.在用户的映射配置文件中配置
<!-- 根据 id 查询 -->
<select id="findById" resultType="com.itheima.domain.User" parameterType="int">
select * from user where id = #{uid}
</select>
3. 在测试类添加测试
模糊查询:
1.在持久层接口中添加模糊查询方法 List<User> findByName(String username);
2.在用户的映射配置文件中配置
<!-- 根据名称模糊查询 -->
<select id="findByName" resultType="com.itheima.domain.User" parameterType="String">
select * from user where username like #{username}
</select>
3.加入模糊查询的测试方法
@Test
public void testFindByName(){
//5.执行查询一个方法
List<User> users = userDao.findByName("%王%"); //注意这里的百分号
for(User user : users){
System.out.println(user);
}
}
查询使用聚合函数
1.在持久层接口中添加模糊查询方法
2.在用户的映射配置文件中配置
<!-- 查询总记录条数 -->
<select id="findTotal" resultType="int">
select count(*) from user;
</select>
3.加入聚合查询的测试方法
@Test
public void testFindTotal(){
int total = userDao.findTotal();
System.out.println(total);
}
parameterType 配置参数
该属性的取值可以 是基本类型,引用类型(例如:String 类型),还可以是实体类类型(POJO 类)(需要使用全限定类名),同时也可以使用实体类的包装类。
传递 pojo 包装对象(多个对象信息封装进一个查询对象中)
- 开发中通过 pojo 传递查询条件 ,查询条件是综合的查询条件,不仅包括用户查询条件还包括其它的查询条件(比如将用户购买商品信息也作为查询条件),这时可以使用包装对象传递输入参数。
1.编写 QueryVo public class QueryVo implements Serializable { private User user; public User getUser() { return user; } public void setUser(User user) { this.user = user; } } 2.编写持久层接口: List<User> findByVo(QueryVo vo); 3.测试包装类作为参数 @Test public void testFindByQueryVo() { QueryVo vo = new QueryVo(); User user = new User(); user.setUserName("%王%"); vo.setUser(user); List<User> users = userDao.findByVo(vo); for(User u : users) { System.out.println(u); } }
resultType 配置结果类型(作用:让类中属性与数据库列名保持一致)
以指定结果集的类型,它支持基本类型和实体类类型(需要全限定类名)。
当是实体类名称时,实体类中的属性名称必须和查询语句中的列名保持一致,否则无法实现封装。
可以使用起别名的方式解决问题
- 在sql语句中起别名(效率高,但查询的多过于麻烦,不宜于维护)
使用别名查询 <!--起的别名与实体类的属性名相同 --> <select id="findAll" resultType="com.itheima.domain.User"> select id as userId,username as userName,birthday as userBirthday, sex as userSex,address as userAddress from user </select>- 使用 resultMap 建立 User 实体和数据库表的对应关系 (多插入了一个标签,效率低,但后期好维护)
1.定义 resultMap <!-- 建立 User 实体和数据库表的对应关系 type 属性:指定实体类的全限定类名 id 属性:给定一个唯一标识,是给查询 select 标签引用时用的。 --> <resultMap type="com.itheima.domain.User" id="userMap"> <id column="id" property="userId"/> <result column="username" property="userName"/> <result column="sex" property="userSex"/> <result column="address" property="userAddress"/> <result column="birthday" property="userBirthday"/> </resultMap> id 标签:用于指定主键字段 result 标签:用于指定非主键字段 column 属性:用于指定数据库列名 property 属性:用于指定实体类属性名称 2. 映射配置 <!-- 不再需要resultType,而是使用resultMap来找到返回类型 --> <select id="findAll" resultMap="userMap"> select * from user </select>
SqlMapConfig.xml配置文件
1. SqlMapConfig.xml 中配置的内容和顺序
-properties(属性)
--property
-settings(全局配置参数)
--setting
-typeAliases(类型别名)
--typeAliase
--package
-typeHandlers(类型处理器)
-objectFactory(对象工厂)
-plugins(插件)
-environments(环境集合属性对象)
--environment(环境子属性对象)
---transactionManager(事务管理)
---dataSource(数据源)
-mappers(映射器)
--mapper
--package
2.properties(属性)(作用:加载外部配置文件)
- 第一种:在SqlMapConfig.xml配置文件中
<properties>
<property name="jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="jdbc.url" value="jdbc:mysql://localhost:3306/eesy"/>
<property name="jdbc.username" value="root"/>
<property name="jdbc.password" value="1234"/>
</properties>
第二种:在classPath下定义 db.properties 文件
jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://localhost:3306/eesy jdbc.username=root jdbc.password=1234在SqlMapConfig.xml中加上properties: <!-- 配置连接数据库的信息 resource 属性:用于指定 properties 配置文件的位置,要求配置文件必须在类路径下 resource="jdbcConfig.properties" url 属性: URL: Uniform Resource Locator 统一资源定位符 http://localhost:8080/mystroe/CategoryServlet (如果是文件,协议就是file:///) 协议 主机 端口 URI URI:Uniform Resource Identifier 统一资源标识符 /mystroe/CategoryServlet 它是可以在 web 应用中唯一定位一个资源的路径 --> <!-- 属性常用resource 也可以用url 效果一样--> <properties url= " file:///D:/IdeaProjects/day02_eesy_01mybatisCRUD/src/main/resources/jdbcConfig.prop erties"> </properties>dataSource 标签就变成了引用上面的配置
<dataSource type="POOLED"> <property name="driver" value="${jdbc.driver}"/> <property name="url" value="${jdbc.url}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> </dataSource>
3.typeAliases(类型别名)(给类型起别名,resultType和parameterType在使用全类名时可直接写类名)
自定义别名
在 SqlMapConfig.xml 中配置: <typeAliases> <!-- 单个别名定义 alias:指定别名 type:原名 使用package标签就不需要typeAlias标签了--> <typeAlias alias="user" type="com.itheima.domain.User"/> <!-- 批量别名定义,扫描整个包下的类,别名为类名(首字母大写或小写都可以) --> <package name="com.itheima.domain"/> <package name=" 包名 "/> </typeAliases>
4.mappers(映射器)(作用:不用单独映射,直接封装映射,注解和Xml配置都起效)
-
用在配置文件的配置
使用相对于类路径的资源
如:<mapper resource="com/itheima/dao/IUserDao.xml" />
用在注解配置 使用 mapper 接口类路径 如:<mapper class="com.itheima.dao.UserDao"/> 注意:此种方法要求 mapper 接口名称和 mapper 映射文件名称相同,且放在同一个目录中。用在批量配置 注册指定包下的所有 mapper 接口 如:<package name="cn.itcast.dao"/> //name:接口文件夹 注意:此种方法要求 mapper 接口名称和 mapper 映射文件名称相同,且放在同一个目录中
5.plugins插件标签
分页插件
导入通用PageHelper坐标
<dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper</artifactId> <version>3.7.5</version> </dependency> <dependency> <groupId>com.github.jsqlparser</groupId> <artifactId>jsqlparser</artifactId> <version>0.9.1</version> </dependency>在mybatis核心配置文件中配置PageHelper插件
<plugins> <plugin interceptor="com.github.pagehelper.PageHelper"> <property name="dialect" value="mysql"/> </plugin> </plugins>测试:配置参数
PageHelper.startPage(1,3);//设置当前页为1,一页3条 //查看分页信息 PageInfo<User> userPageInfo = new PageInfo<>(list); System.out.println("当前页:"+userPageInfo.getPageNum()); System.out.println("每页显示条数:"+userPageInfo.getPageSize()); System.out.println("总条数:"+userPageInfo.getTotal()); System.out.println("总页数:"+userPageInfo.getPages());
Mybatis 的连接池技术
- 在 Mybatis 的 SqlMapConfig.xml 配置文件中,通过
来实 现 Mybatis 中连接池的配置。 - Mybatis 连接池的分类(
) - UNPOOLED 不使用连接池的数据源
- POOLED 使用连接池的数据源
- JNDI 使用 JNDI 实现的数据源 (根据服务器获得不同的连接池,c3p0,druid)
Mybatis 的事务控制
Mybatis 自动提交事务的设置
在测试类的init方法中,将openSession增加参数true session = factory.openSession(true);- 虽然这也是一种方式,但就 编程而言,设置为自动提交方式为 false再根据情况决定是否进行提交,这种方式更常用。因为我们可以根据业务 情况来决定提交是否进行提交。
动态 SQL(根据不同条件来追加sql语句)
标签(拼接条件语句) - 持久层 Dao 映射配置
<!--注意:BindingException异常的原因:select的id属性和方法名不一样导致--> <select id="findByUser" resultType="user" parameterType="user"> select * from user where 1=1 <if test="username!=null and username != '' "> and username like #{username} </if> <if test="address != null"> and address like #{address} </if> </select> 注意:<if>标签的 test 属性中写的是对象的属性名标签 (简化上面 where 1=1 的条件拼装) - 持久层 Dao 映射配置
<where> <if test="username!=null and username != '' "> and username like #{username} </if> <if test="address != null"> and address like #{address} </if> </where>标签 (拼接 in 条件语句:搜索id为1或2或3的用户) 在 QueryVo 中加入一个 List 集合用于封装参数
public class QueryVo implements Serializable { private List<Integer> ids; public List<Integer> getIds() { return ids; } public void setIds(List<Integer> ids) { this.ids = ids; } }持久层 Dao 映射配置
<!-- 查询所有用户在 id 的集合之中 --> <select id="findInIds" resultType="user" parameterType="queryvo"> <!-- select * from user where id in (1,2,3,4,5); --> select * from user <where> <if test="ids != null and ids.size() > 0"> <foreach collection="ids" open="id in ( " close=")" item="uid" separator=","> #{uid} </foreach> </if> </where> </select> SQL 语句: select 字段 from user where id in (?) <foreach>标签用于遍历集合,它的属性: collection:代表要遍历的集合元素,注意编写时不要写#{} open:代表语句的开始部分 close:代表结束部分 item:代表中间插入的数(随意写,#{要和item起的名一样}) separator:分隔符
sql语句抽取
作用:将多次用到的语句抽取出来
<sql id="selectUser">select * from user</sql> 使用时:<include refid="selectUser"></include>
多表查询
一对一查询(多对一)
需求 :查询所有账户信息,关联查询下单用户信息
使用 resultMap,定义专门的 resultMap 用于映射一对一查询结果
- 创建表
CREATE TABLE `orders` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ordertime` varchar(255) DEFAULT NULL, `total` double DEFAULT NULL, `uid` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `uid` (`uid`), /*外键的格式: CONSTRAINT 外键名 FOREIGN KEY (外键名) REFERENCES 目标库名 (目标库外键名) */ CONSTRAINT `orders_ibfk_1` FOREIGN KEY (`uid`) REFERENCES `user` (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;```
- 修改 Account 类
增加用户信息 private User user; public User getUser() { return user; } public void setUser(User user) { this.user = user; }- 接口方法返回值
将返回值改 为了 Account 类型。 因为 Account 类中包含了一个 User 类的对象,它可以封装账户所对应的用户信息。- 重新定义 AccountDao.xml 文件
<!-- 建立对应关系 --> <resultMap type="account" id="accountMap"> <!--column:数据表字段名称,property:当前类属性名称--> <id column="aid" property="id"/> <result column="uid" property="uid"/> <result column="money" property="money"/> <!-- 它是用于指定从表方的引用实体属性的 --> <!--property:当前的实体属性名称,javaTape:当前的实体属性类型--> <association property="user" javaType="user"> <id column="id" property="id"/> <result column="username" property="username"/> <result column="sex" property="sex"/> <result column="birthday" property="birthday"/> <result column="address" property="address"/> </association> </resultMap> <select id="findAll" resultMap="accountMap"> select u.*,a.id as aid,a.uid,a.money from account a,user u where a.uid =u.id; </select>注意:resultMap内的每个对照关系,尤其是外键对应,否则数据会不对应
- 在 AccountTest 类中加入测试方法
@Test public void testFindAll() { List<Account> accounts = accountDao.findAll(); for(Account au : accounts) { System.out.println(au); System.out.println(au.getUser()); } }出现的错误:Cause: org.apache.ibatis.executor.ExecutorException
原因:没有找到空构造函数
解决:将两个实体类加上空参构造函数即可
一对多查询
需求: 查询所有用户信息及用户关联的账户信息。
分析: 用户信息和他的账户信息为一对多关系,并且查询过程中如果用户没有账户信息,此时也要将用户信息 查询出来,我们想到了左外连接查询比较合适
- 修改User类
增加账户信息 private List<Account> accounts; public List<Account> getAccounts() { return accounts; } public void setAccounts(List<Account> accounts) { this.accounts = accounts; }- 重新定义 AccountDao.xml 文件
<resultMap type="user" id="userMap"> <id column="id" property="id"></id> <result column="username" property="username"/> <result column="address" property="address"/> <result column="sex" property="sex"/> <result column="birthday" property="birthday"/> <!-- collection 是用于建立一对多中集合属性的对应关系 ofType 用于指定集合元素的数据类型 --> <collection property="accounts" ofType="account"> <id column="aid" property="id"/> <result column="uid" property="uid"/> <result column="money" property="money"/> </collection> </resultMap> <!-- 配置查询所有操作 --> <select id="findAll" resultMap="userMap"> select u.*,a.id as aid ,a.uid,a.money from user u left outer join account a on u.id =a.uid </select> collection 部分定义了用户关联的账户信息。表示关联查询结果集 property="accList" : 关联查询的结果集存储在 User 对象的上哪个属性。 ofType="account" : 指定关联查询的结果集中的对象类型即List中的对象类型。此处可以使用别名,也可以使用全限定名。
多对多
需求: 实现查询所有角色并且加载它所分配的用户信息。
分析: 查询角色我们需要用到Role表,但角色分配的用户的信息我们并不能直接找到用户信息,而是要通过中 间表(USER_ROLE 表)才能关联到用户信息。
- 编写角色实体类
private List<User> users; public List<User> getUsers() { return users; } public void setUsers(List<User> users) { this.users = users; }- 编写 Role 持久层接口
- 编写映射文件
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.itheima.dao.IRoleDao"> <!--定义 role 表的 ResultMap--> <resultMap id="roleMap" type="role"> <!--注意这里是rid,因为sql语句中重命名了,否则查询不到总裁信息--> <id property="roleId" column="rid"></id> <result property="roleName" column="role_name"></result> <result property="roleDesc" column="role_desc"></result> <collection property="users" ofType="user"> <id column="id" property="id"></id> <result column="username" property="username"></result> <result column="address" property="address"></result> <result column="sex" property="sex"></result> <result column="birthday" property="birthday"></result> </collection> </resultMap> <!--查询所有--> <select id="findAll" resultMap="roleMap"> select u.*,r.id as rid,r.role_name,r.role_desc from role r left outer join user_role ur on r.id = ur.rid left outer join user u on u.id = ur.uid </select> </mapper>总结:
- 修改实体类,一对一增加实体类属性,一对多、多对多增加集合属性
一对一使用association,一对多和多对多使用collection,column属性是查询的结果集列名
Mybatis 延迟加载
延迟加载: 就是在需要用到数据时才进行加载,不需要用到数据时就不加载数据。延迟加载也称懒加载.
好处:先从单表查询,需要时再从关联表去关联查询,大大提高数据库性能,因为查询单表要比关联查询多张表速 度要快。
坏处: 因为只有当需要用到数据时,才会进行数据库查询,这样在大批量数据查询时,因为查询工作也要消耗 时间,所以可能造成用户等待时间变长,造成用户体验下降
通常:一对一正常立即加载 一对多使用延迟加载
使用 assocation 实现延迟加载
- SqlMapConfig.xml 文件中添加延迟加载的配置
<settings> <setting name="lazyLoadingEnabled" value="true"/> <setting name="aggressiveLazyLoading" value="false"/> </settings>- 持久层映射文件
resultMap中: <!-- 它是用于指定从表方的引用实体属性的 select参数是调用的方法--> <association property="user" javaType="user" select="com.itheima.dao.IUserDao.findById" column="uid"> </association>- 编写select对应的方法
使用 Collection 实现延迟加载
- SqlMapConfig.xml 文件中添加延迟加载的配置
- 持久层映射文件
<!-- collection 是用于建立一对多中集合属性的对应关系 ofType 用于指定集合元素的数据类型 select 是用于指定查询账户的唯一标识(账户的 dao 全限定类名加上方法名称) column 是用于指定使用哪个字段的值作为条件查询 --> <collection property="accounts" ofType="account" select="com.itheima.dao.IAccountDao.findByUid" column="id"> </collection>- 编写select对应的方法
Mybatis 缓存
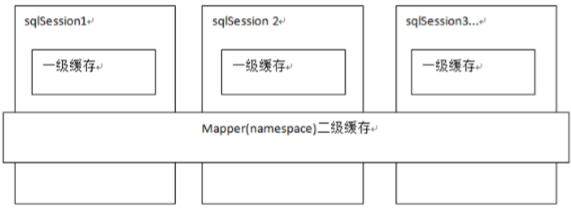
一级缓存:一级缓存是 SqlSession 范围的缓存,当调用 SqlSession 的修改,添加,删除,commit(),close()等方法时,就会清空一级缓存。
也可手动清除一级缓存:
sqlSession.clearCache();//此方法也可以清空缓存 userDao = sqlSession.getMapper(IUserDao.class);
二级缓存:二级缓存是 mapper 映射级别的缓存,多个 SqlSession 去操作同一个 Mapper 映射的 sql 语句,多个 SqlSession 可以共用二级缓存,二级缓存是跨 SqlSession 的。
二级缓存的开启与关闭
- 在 SqlMapConfig.xml 文件开启二级缓存
<settings> <!-- 开启二级缓存的支持 --> <setting name="cacheEnabled" value="true"/> </settings> 因为 cacheEnabled 的取值默认就为 true,所以这一步可以省略。为 true 代表开启二级缓存- 配置相关的 Mapper 映射文件
<!--<cache>标签表示当前这个 mapper 映射将使用二级缓存,区分的标准就看 mapper 的 namespace 值。 --> <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.itheima.dao.IUserDao"> <!-- 开启二级缓存的支持 --> <cache></cache> </mapper>- 配置 statement 上面的 useCache 属性
<!-- 根据 id 查询 --> <select id="findById" resultType="user" parameterType="int" useCache="true"> select * from user where id = #{uid} </select> 将 UserDao.xml 映射文件中的<select>标签中设置 useCache=”true”代表当前这个 statement 要使用二级缓存,如果不使用二级缓存可以设置为 false。 注意:针对每次查询都需要最新的数据 sql,要设置成 useCache=false,禁用二级缓存。- 二级缓存需序列化接口
因为二级缓存保存到的是数据,不是map,当读取时会将数据重新封装成对象。 public class User implements Serializable { }
Mybatis 注解开发
注意:使用注解开发就不能使用xml配置,mapper映射中使用package,如果同时存在会报错
mybatis 的常用注解说明
*@Insert:实现新增 *@Update:实现更新 *@Delete:实现删除 *@Select:实现查询 *@Result:实现结果集封装 *@Results:可以与@Result 一起使用,封装多个结果集 @ResultMap:实现引用@Results 定义的封装 *@One:实现一对一结果集封装 *@Many:实现一对多结果集封装 @SelectProvider: 实现动态 SQL 映射 *@CacheNamespace:实现注解二级缓存的使用 trueMybatis 注解实现基本 CRUD
编写接口
@Select("select * from user where id = #{uid} ") //解决类属性名与数据库列名不对应的方式 @Results({ @Result(id=true,column="id",property="userId"), @Result(column="username",property="userName"), @Result(column="sex",property="userSex"), @Result(column="address",property="userAddress"), @Result(column="birthday",property="userBirthday") }) //其他的方法可直接用 @Results("userMap")编写 SqlMapConfig 配置文件
<!-- 配置映射信息 --> <mappers> <package name="com.itheima.dao"/> </mappers>编写测试方法
注解实现复杂关系映射开发
复杂关系映射的注解说明
@Results 注解 代替的是标签<resultMap> 该注解中可以使用单个@Result 注解,也可以使用@Result 集合 @Results({@Result(),@Result()})或@Results(@Result()) @Result 注解 代替了 <id>标签和<result>标签 @Result 中 属性介绍: id 是否是主键字段 column 数据库的列名 property 需要装配的属性名 one 需要使用的@One 注解 @Result(one=@One()) many 需要使用的@Many 注解 @Result(many=@many()) @One 注解(一对一) 代替了<assocation>标签,是多表查询的关键,在注解中用来指定子查询返回单一对象。 @One 注解属性介绍: select 指定用来多表查询的 sqlmapper select 是用于方法的唯一标识(dao全限定类名加上方法名称) fetchType(可省) 会覆盖全局的配置参数 lazyLoadingEnabled。 参数:FetchType.LAZY(延迟)、EAGER(立即) 使用格式: @Result(column="结果集中查询的条件(uid)",property="封装的属性名(user)",one=@One(select="dao方法的全限定类名" fetchType=) @Many 注解(一对多) 代替了<Collection>标签,是多表查询的关键,在注解中用来指定子查询返回对象集合。 注意:聚集元素用来处理“一对多”的关系。需要指定映射的 Java 实体类的属性,属性的 javaType (一般为 ArrayList)但是注解中可以不定义; 使用格式: @Result(property="封装的属性名(orderList)",column="结果集中查询的条件(id)",many=@Many(select="dao方法的全限定类名")总结:使用一对一和一对多,首先要确定sql语句的两步骤,比如一对多当中的:查询用户下的所有订单,要先查询用户信息select * from user,之后根据Id查询订单信息select * from order where uid = #{id}
运行机制
- 封装JDBC操作
- 利用反射打通Java类与SQL语句之间的相互转换,目的就是让我们对执行SQL语句时对输入输出的数据管理更加方便
原理详解:
mybatis应用程序通过SqlSessionFactoryBuilder从xml配置文件(也可以用Java文件配置的方式,需要添加@Configuration)来构建SqlSessionFactory(SqlSessionFactory是线程安全的);
然后,SqlSessionFactory的实例直接开启一个SqlSession,再通过SqlSession实例获得Mapper对象并运行Mapper映射的SQL语句,完成对数据库的CRUD和事务提交,之后关闭SqlSession。


